نظر
نظر
دانشمند داده در مقابل دانشمند کامپیوتر. در اینجا تفاوت وجود دارد.
دیدگاه یک متخصص داده های حرفه ای در مورد تفاوت بین این دو زمینه و نقش برجسته.
 عکس توسط Oğuzhan Akdoğan در Unsplash [1].
عکس توسط Oğuzhan Akdoğan در Unsplash [1]. فهرست مطالب
مقدمه
علم داده و علوم کامپیوتر اغلب دست به دست هم می دهند ، اما واقعا چه چیزی آنها را متفاوت می کند؟ وجه اشتراک آنها چیست؟ پس از تجربه چندین نقش مختلف در علم داده در شرکت های مختلف ، من به موضوعات کلی فرایند علم داده ، همراه با نحوه ترکیب علوم رایانه در آن فرایند نیز پی برده ام. توجه به تفاوتهای بین این دو موقعیت ، و همچنین زمانی که یکی به دیگری نیاز دارد و بالعکس ، بسیار مهم است. معمولاً یک دانشمند داده از یادگیری علوم رایانه و سپس تخصص در الگوریتم های یادگیری ماشین سود خواهد برد. با این حال ، برخی از دانشمندان داده قبل از یادگیری نحوه کدگذاری ، مستقیماً به آمار می پردازند و بر نظریه علم داده و الگوریتم های یادگیری ماشین تمرکز می کنند. این روش من بود ، با یادگیری علوم کامپیوتر و برنامه نویسی پس از آن. گفته می شود ، آیا یک دانشمند داده نیاز به علم کامپیوتر دارد؟ پاسخ کوتاه بله است. در حالی که علوم رایانه می تواند علم داده را شامل شود ، به ویژه در زمینه هوش مصنوعی حیاتی است ، من معتقدم موضوع اصلی علوم کامپیوتر مهندسی نرم افزار است. اگر مایل هستید در مورد تفاوت بین (این دو نقش) و همچنین شباهت های مربوطه بیشتر بدانید ، به خواندن ادامه دهید. من همچنین عمیقاً به تمرکز هر یک از این موقعیت ها ، از جمله ابزارها ، مهارت ها ، زبان ها ، مراحل و مفاهیم متمرکز می پردازم.
Data Scientist
 عکس توسط مارکوس اسپیسکه در Unsplash [2].
عکس توسط مارکوس اسپیسکه در Unsplash [2]. بنابراین یک دانشمند داده واقعا چه می کند؟ ما کلمات پر سر و صدا را اغلب در صنعت فناوری می شنویم ، اما آیا آنها در واقع کلیدواژه هایی هستند که ما در کارهای روزمره خود به کار می بریم؟ جواب بله یا خیر است. بدون شک بسیاری از ابزارها و زبانهای اصلی وجود دارد که حداقل روزانه از آنها استفاده می کنم. به عنوان یک دانشمند داده ، من ملزم به کشف داده های شرکت هستم و در عین حال نحوه تأثیر داده ها بر محصول را نیز متصل می کنم. در نهایت ، یک دانشمند داده به مطالعه داده های فعلی ، یافتن داده های جدید ، حل مسائل تجاری و محصول ، همه با استفاده از الگوریتم های یادگیری ماشین (به عنوان مثال ، جنگل تصادفی) تشویق می شود. برخی از مشکلات مشابه را دانشمندان کامپیوتر نیز می توانند حل کنند. اما به خاطر عنوان شغلی ، داشتن شخصی که صرفاً بر الگوریتم های یادگیری ماشین متمرکز است ، به عنوان روش ایجاد یک فرایند دستی نه تنها کارآمدتر ، بلکه دقیق تر ضروری است.
همانطور که می بینید ، گاهی اوقات این فرایند را می توان با دیگران مانند مهندس هوش مصنوعی ، مهندس داده ، دانشمند کامپیوتر ، مهندس MLOps ، مهندس نرم افزار و غیره به اشتراک گذاشت. بر. آنچه نقش دانشمند داده را منحصر به فرد می کند ، تمرکز نظریه یادگیری ماشین و تأثیر آن بر مشکلات تجاری است. > SQL
در حالی که فرایند علم داده بیشتر "مانند سنگ" تنظیم شده است ، مانند فرایند علمی چگونه است ، ابزارهایی که یک دانشمند داده استفاده می کند برای تفسیر بیشتر در دسترس است. با توجه به آنچه گفته شد ، من می گویم اکثر دانشمندان داده بر استفاده از SQL ، Python و Jupyter Notebook (یا چیزی مشابه) تمرکز می کنند. این تمرکز به این دلیل است که این ابزارها یا زبانها را می توان برای هر شغلی استفاده کرد. با این حال ، برخی از شرکت ها دارای ترجیحات یا الزامات خاصی هستند که به شما امکان می دهد به عنوان مثال Google Data Studio را از Tableau انتخاب کنید. در مرحله بعد ، ما به طور خاص در مورد نقش دانشمند کامپیوتر صحبت خواهیم کرد.
دانشمند کامپیوتر
 عکس توسط کاری شی در Unsplash [3].
عکس توسط کاری شی در Unsplash [3]. در حالی که رشته علوم رایانه از عنوان دانشمند کامپیوتر رایج تر است ، هنوز نقش هایی وجود دارد که بر روی این نقش تمرکز می کنند. صرفا گفته می شود ، علوم کامپیوتر در نیروی کار تمایل دارد به طور خاص مهندسی نرم افزار را هدف قرار دهد. سایر نقشهایی که می تواند تحت رایانه کامپیوتر انجام شود شامل موارد زیر است: این تنوع تعریف دانشمند رایانه را کمی دشوارتر می کند ، از جمله اینکه چگونه علم داده می تواند شامل عملیات یادگیری ماشین ، مهندسی داده ، تجزیه و تحلیل داده ها و غیره باشد. در نهایت ، این وظیفه شما و شرکتی است که در آن کار می کنید ، نقش خود را در علوم کامپیوتر تعیین می کند. البته توصیف شغل راهی آسان برای فهمیدن نقش فرعی خاص است.
اگرچه این فرایند دقیقاً شبیه به یک متخصص داده تخصصی نیست ، اما هنوز برخی از جنبه های وسیع تر یک فرایند فنی تر را شامل می شود ، از جمله ، اما نه محدود به درک نرم افزار ، داده ها ، و اجرای بهبود ، در حالی که پس از آن ، تجزیه و تحلیل و گزارش تأثیر آن. :
ابزارها و زبانهای بیشماری وجود دارد که دانشمندان کامپیوتر می توانند از آنها استفاده کنند. بار دیگر ، واقعاً بستگی به تمرکز شما دارد - آیا مهندسی نرم افزار است ، آیا اینطور استتجزیه و تحلیل شبکه ، آیا IT است؟ امیدوارم نقشی برای شما وجود داشته باشد که نه تنها شما واجد شرایط آن هستید ، بلکه وظیفه ای را ترجیح می دهید که تحت آن فعالیت کنید. در مرحله بعد ، من عمیق تر به شباهت ها و تفاوت های بین موقعیت علم دانش و رایانه کامپیوتر می پردازم.
شباهت ها و تفاوت ها
 عکس توسط اریک پروزت در Unsplash [4].
عکس توسط اریک پروزت در Unsplash [4]. اکنون که در مورد موضوعات و انتظارات اصلی این دو نقش بحث کرده ایم: علم داده و علوم کامپیوتر ، ما اکنون شباهت ها و تفاوت های بین آنها را برجسته می کنیم. البته ، نکات بیشتری برای بحث وجود دارد ، اما اینها برخی از مواردی است که به عنوان بازیگران اصلی از تجربه من به ذهن می آید.
شباهت های بین نقش ها زمینه فناوری را برجسته می کند این نقشها در داخل هستند.
از آنجا که این نقشها شامل سایر نقشهای فرعی است ، می توانند در یک شرکت بسیار متفاوت از یکدیگر باشند و شگفت آور باشند در یک شرکت دیگر همپوشانی دارد. با این حال ، آنها همچنین دارای برخی از ویژگی های همان جنبه ها هستند. مفهوم اصلی یک دانشمند داده حل مشکلات تجاری با استفاده از الگوریتم های یادگیری ماشین است ، در حالی که موضوع اصلی یک دانشمند کامپیوتر یا جهت برنامه نویسی شی گرا و مهندسی نرم افزار است یا بیشتر به سمت IT که نیاز به دانش عمومی در مورد همه چیز دارد. یک کامپیوتر.
امیدوارم این مقاله برای شما جالب و مفید واقع شده باشد. به خاطر داشته باشید که این مقاله بر اساس نظر من و تجربیات شخصی هر دو نقش است. اگر مخالف یا موافق هستید ، در صورت دلایل و موارد خاصی که می خواهید اضافه کنید ، در زیر نظر دهید. آیا بیشتر دوست دارید یک دانشمند داده باشید یا یک دانشمند کامپیوتر؟ آیا فکر می کنید آنها باید در یک نقش ادغام شوند؟ آیا واقعا تفاوتی وجود دارد؟ به عنوان یک دانشمند کامپیوتر ، تمرکز شما بر چیست؟ IT است یا چیزی شبیه به Networking؟جالب است که برخی از بینش ها را از دیگران دریافت کنید تا همه بتوانند از دیگران یاد بگیرند تا بهترین نمایانگر شباهت ها و تفاوت های بین علوم داده و علوم کامپیوتر باشند. از شما برای خواندن متشکرم و در صورت تمایل می توانید مشخصات من را مطالعه کنید یا مقالات دیگر را بخوانید و در صورت داشتن هرگونه سوال در مورد آنها با من تماس بگیرید. علم با خیال راحت و همچنین مقاله مشابه دیگر من در مورد Data Science vs Machine Learning Ops Engineer را بررسی کنید [5]. این مقاله تفاوتها و شباهتهای بین Data Science و MLOps را مشخص می کند ، که هر دو ابزار و تجربیات زیادی را به اشتراک می گذارند ، در عین حال متفاوت است:
متشکرم!
مراجع
[1] عکس Oğuzhan Akdoğan در Unsplash ، (2019)
[2] عکس توسط مارکوس اسپیسکه در Unsplash ، (2018)
[3] عکس توسط کاری شی در Unsplash ، (2017)
[4] عکس از اریک پروزت در Unsplash ، (2020)
[5] M.Przybyla ، Data Scientist vs Machine Learning Ops Engineer. در اینجا تفاوت وجود دارد. ، (2021)
یافتن خط قوی با استفاده از تکنیک های پیشرفته بینایی رایانه ای: به روزرسانی در اواسط پروژه
یافتن خط قوی با استفاده از تکنیک های پیشرفته بینایی رایانه ای: به روزرسانی در اواسط پروژه
یافتن خط برای توسعه الگوریتم ها برای روبات های خودران یا اتومبیل های خودران بسیار مهم است. الگوریتم یافتن خط باید برای تغییر شرایط نور ، شرایط آب و هوا ، سایر خودروها/وسایل نقلیه در جاده ، انحنای جاده و نوع جاده خود قوی باشد. در این پست ، ما یک الگوریتم مبتنی بر تکنیک های پیشرفته بینایی رایانه برای شناسایی خطوط چپ و راست از فیلم دوربین نصب شده در خط تیره ارائه می دهیم. ما الگوریتم خط یابی را در مراحل زیر پیاده سازی کردیم ،
در ادامه هر مرحله را با جزئیات مرور می کنیم. نتیجه نهایی فرآیند بالا در زیر ارائه شده است ،
ویدئوی زیر یک نمای تشخیصی از تمام مراحل تهیه ویدیوی بالا ارائه می دهد.
مرحله 1: عدم تحریف تصویر دوربین و اعمال آن تبدیل پرسپکتیو.
وقتی لنز دوربین تصویری را ثبت می کند ، تصویر واقعی را ضبط نمی کند ، بلکه اعوجاج تصویر اصلی را ثبت می کند. نقاط مرکز تصویر دارای اعوجاج کمتری هستند در حالی که نقاط دورتر از مرکز دارای اعوجاج بیشتری هستند. این اعوجاج می تواند ناشی از تفاوت در فاصله از مرکز دوربین ، خم شدن دیفرانسیل اشعه در محل مختلف لنز یا اعوجاج چشم انداز باشد. مقاله خوبی در مورد انواع مختلف اعوجاج در اینجا یافت می شود.
بنابراین ، اولین مرحله در پردازش تصویر ، عدم تحریف تصویر اصلی است. شرح خوبی از الگوریتم مورد استفاده برای عدم تحریف تصویر دوربین را می توانید در اینجا پیدا کنید. برای الگوریتم ما ، ابتدا ماتریس اعوجاج دوربین و پارامترهای اعوجاج را با استفاده از تصاویر ارائه شده روی صفحه شطرنج محاسبه کردیم. سپس ماتریس دوربین را بارگذاری کرده و از آن برای عدم تحریف تصاویر استفاده می کنیم. شکل زیر نتیجه عدم تحریف را نشان می دهد. آخرین پانل تفاوت بین تصویر اصلی و تحریف نشده را نشان می دهد.
 حذف اعوجاج تصویر < /img>
حذف اعوجاج تصویر < /img> در مرحله بعد ما از دگرگونی چشم انداز برای به دست آوردن نمای پرنده از جاده استفاده کردیم. ما این کار را با شناسایی 4 نقطه در تصویر اصلی دوربین و سپس کشیدن تصویر به گونه ای انجام دادیم که ناحیه بین 4 نقطه یک قسمت مستطیل شکل ایجاد می کند.
 تغییر چشم انداز برای مشاهده نمای پرنده
تغییر چشم انداز برای مشاهده نمای پرنده هنگامی که نمای بالایی به دست آمد ، به خطوط idenfiy ادامه دادیم.
< مرحله 2: تبدیل به فضای رنگی HSV و استفاده از ماسک های رنگیمرحله بعدی تبدیل تصویر RGB از نمای پرنده به رنگ بندی HSV بود. HSV به رنگ ، اشباع و ارزش اشاره دارد. طرح HSV به عنوان روشی بصری تر برای نشان دادن رنگ توسعه یافت. Hue (یا H) نشان دهنده رنگ خاص ، اشباع (یا S) مقدار رنگ و مقدار (یا V) روشنایی نسبت به روشنایی مشابه استسفید. بنابراین ، با تبدیل تصاویر به مقیاس HSV ، تمایز رنگ خوبی به دست می آید. ما از فضای رنگ HSV برای شناسایی رنگهای زرد و سفید استفاده کردیم. ما ماسک زرد را به عنوان
yellow_hsv_low = np.array ([0 ، 80 ، 200]) استفاده کردیم yellow_hsv_high = np.array ([40 ، 255 ، 255]) res = apply_color_mask (image_HSV ، warped ، yellow_hsv_low ، yellow_hsv_high)
جایی که apply_color_mask پیکسل هایی با شدت مشخص شده بین مقادیر کم و زیاد را برمی گرداند. نتیجه استفاده از ماسک زرد ،
 اعمال ماسک زرد
اعمال ماسک زرد از آنجا که ماسک زرد در شرایط مختلف نور بسیار قوی است ، زیرا با تغییر کانال روشنایی ، در حالی که رنگ یا رنگ را ثابت نگه می دارید ، تصاویر مختلف رنگ زرد ایجاد می شود. شکلهای زیر تأثیر استفاده از ماسک زرد ما را در شرایط مختلف نور نشان می دهد.
 زرد ماسک در قسمت سایه دار و روشن جاده
زرد ماسک در قسمت سایه دار و روشن جاده  ماسک زرد در قسمت روشن جاده < /img>
ماسک زرد در قسمت روشن جاده < /img> به طور مشابه یک ماسک سفید با استفاده از آستانه به عنوان
white_hsv_low = np.array ([20 ، 0 ، 200]) white_hsv_high = np.array ([255 ، 80 ، 255])
برای شناسایی خطوط سفید ،
 استفاده از ماسک سفید ،
استفاده از ماسک سفید ، هنگامی که ماسک های زرد و سفید اعمال شد ، خطوط ماسک رنگی با ترکیب دو ماسک خط به شرح زیر بدست آمد.
 خط ترکیبی ماسک های رنگی
خط ترکیبی ماسک های رنگی مرحله 3: از فیلترهای اصیل استفاده کنید برای بدست آوردن خط/لبه های احتمالی
مرحله بعدی استفاده از فیلترهای Sobel برای بدست آوردن خطوط/لبه های احتمالی بود. ماسک های رنگی بالا برای انتخاب خطوط خط خوب است ، اگر هیچ علامت زرد یا سفید دیگری در جاده وجود ندارد. این همیشه ممکن نیست زیرا جاده ها می توانند نوشته هایی به رنگ سفید یا زرد روی آنها داشته باشند. بنابراین برای جلوگیری از سردرگمی ، ما همچنین از فیلترهای Sobel برای تشخیص لبه استفاده کردیم. فیلترهای Sobel در پردازش تصویر برای به دست آوردن لبه های یک تصویر با انجام حرکت 2 بعدی تصویر اصلی و اپراتور Sobel (یا فیلترها) استفاده می شوند. این عملیات را می توان به صورت
 فیلتر Sobel ، دایره نشان دهنده عملیات پیچش
فیلتر Sobel ، دایره نشان دهنده عملیات پیچش فیلتر Sobel در امتداد جهت x- و y- شیب یا تغییر در شدت تصویر را در جهت x- و y- ایجاد می کند. این شدت ها را می توان با اندازه و جهت آستانه کرد تا تصویری باینری که در لبه ها برابر 1 است به دست آورد. ما فیلترهای Sobel را اعمال کرده و مقدار شیبها را در جهت x- و y- برای کانالهای S و L تصویر HLS تعیین می کنیم. ما کانال HLS را انتخاب کردیم زیرا در آزمایش های قبلی مشخص شد که HLS color colors برای تشخیص لبه ها قوی تر است.
 فیلتر Sobel اعمال شده در کانال L و S تصویر
فیلتر Sobel اعمال شده در کانال L و S تصویر مرحله 4: ترکیب فیلترهای Sobel و ماسک های رنگی
در ادامه ماسک های دودویی فیلترهای Sobel و ماسک های رنگی را ترکیب کردیم برای به دست آوردن یک شاخص قوی تر برای خطوط. انتظار می رود خطوط دارای علامت های سفید یا زرد در زمینه تیره باشند ، بنابراین انتظار می رود شیب های زیادی را نشان دهند. ماسک تصویر و رنگ Sobel ترکیبی برای خط سفید و زرد در زیر نشان داده شده است.
 ماسک های خطی از فیلترهای Sobel و ماسک های رنگی
ماسک های خطی از فیلترهای Sobel و ماسک های رنگی آخرین ترکیب ماسک خط و لبه از ماسک رنگ و فیلترهای Sobel در زیر ارائه شده است. همانطور که مشهود است ، مناطق موجود در تصویر اصلی که در آن خطوط مورد انتظار است با خطوط ضخیم ضخیم برجسته می شوند. ما توانستیم این خطوط برجسته را بدست آوریم زیرا تشخیص لبه را با آن ترکیب کردیمماسک های رنگی.
 ماسک نهایی خط ترکیبی
ماسک نهایی خط ترکیبی مرحله 5: برای حذف هرگونه علامت گذاری یا ویژگی که ممکن است به دلیل دیگر مصنوعات موجود در تصویر باشد ، از پنجره استفاده کنید.
در ماسک ترکیبی نهایی ، بسیاری از ویژگی های لبه را مشاهده کردیم که می تواند به دلیل دیگر مصنوعات ، برجسته باشد. یکی خط افقی به دلیل کاپوت خودرو بود. بنابراین ما مقدار متوسط همه پیکسل ها را در طول جهت x محاسبه کرده و از یک فیلتر میانگین متحرک برای بدست آوردن توزیع یکنواخت شدت در امتداد جهت x استفاده کردیم. سپس ما آستانه 0.05 را برای شناسایی مناطقی که ممکن است دارای خطوط خط باشند ، اعمال کنیم. این مرزهای منطقه با خطوط آبی نشان داده شده است.
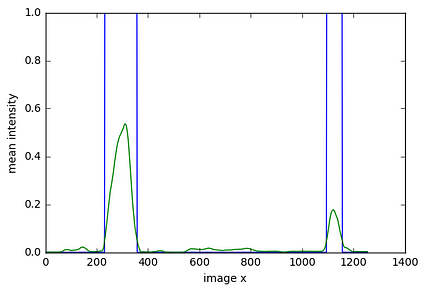 نمودار شدت در جهت X < /img>
نمودار شدت در جهت X < /img> ما از لبه های چپ و راست این قله ها به عنوان محدوده برای انتخاب نقاط برای علامت گذاری خط چپ و راست استفاده کردیم. با حذف نقاط علامت گذاری در خط چپ و راست ، نقاطی را که خطوط را نشان می دهند به عنوان
 علامت گذاری خط چپ و راست
علامت گذاری خط چپ و راست مرحله 6: برای محاسبه خط چپ و راست از رگرسیون چند جمله ای استفاده کنید
سپس از رگرسیون چند جمله ای برای بدست آوردن تناسب درجه دوم برای تقریب خطوط خط استفاده کردیم. ما از تابع برازش چند جمله ای ساده numpy برای محاسبه برازش درجه دو برای خط چپ و راست استفاده کردیم. هنگامی که تناسب درجه دو برای خطوط چپ و راست به دست آمد ، آنها را روی تصویر کشیدیم و منطقه را بین خطوط چپ و راست با رنگ فیروزه ای به صورت زیر علامت گذاری کردیم.
 ترسیم مجدد خطوط خط و بازگشت مجدد روی تصویر اصلی
ترسیم مجدد خطوط خط و بازگشت مجدد روی تصویر اصلی مرحله 7: برای حذف نویز بین ، قاب را برای هموارسازی فریم اعمال کنید تصاویر را بکشید و خطوط را بر روی تصویر ترسیم کنید.
در مرحله بعد ، از طریق فیلتر مرتبه اول ، فریم را برای هموارسازی فریم اعمال کردیم. ما همچنین یک روال رد اختلال را در نظر گرفتیم که هر گونه چند جمله ای را که ضرایب آن از چارچوب قبلی بیش از 5 devi متفاوت بود ، کنار گذاشت.
مرحله 8: محاسبه انحنای خط و انحراف از خط
در نهایت ، ما شعاع انحنا و انحراف از خط را محاسبه کرده و یک سیستم هشدار خروج از خط ساده را اجرا کردیم که در صورت انحراف از خط از 30 سانتی متر ، منطقه فیروزه ای را به قرمز تبدیل می کند.
بازتاب ها
این یک پروژه بسیار جالب و سرگرم کننده بود. جالب ترین بخش این بود که ببینیم چگونه تکنیک های توسعه یافته در یک پروژه ساده قبلی در سناریوی کلی تری به کار گرفته شده است. کار روی این پروژه هنوز به پایان نرسیده است. الگوریتم فعلی آنقدر قوی نیست که بتواند ویدیوها را به چالش بکشد ، اما عملکرد فوق العاده ای دارد. ما در گزارش نهایی خود به جزئیات یک الگوریتم قوی تر می پردازیم.
قدردانی:
از Udacity بسیار سپاسگزارم که مرا برای اولین گروه انتخاب کرد ، این به من امکان اتصال داد با بسیاری از افراد همفکر مثل همیشه ، از بحث با هنریک تانرمن و جان چن چیزهای زیادی آموخت. همچنین از دریافت کمک مالی GPU NVIDA سپاسگزارم. اگرچه ، این برای کار است ، اما من از آن برای Udacity نیز استفاده می کنم.
تشکر ویژه از یکی از دانش آموزان جان چن. جان یک راه حل ساده برای پیاده سازی نمای تشخیصی خط لوله ارسال کرده بود ، اما هنگامی که انجمن از قدیمی تر منتقل شد ، حذف شد. اگرچه ، جان در تعطیلات بود ، اما فوراً کد را بارگذاری کردقطعه ای در انجمن جدید و پیوند را برای من ارسال کرد.

وضعیت بینایی رایانه ای - CVPR 2021
وضعیت بینایی رایانه ای - CVPR 2021
توسط آذین عسگریان و رهیت صحا
Computer Vision (CV) منطقه ای از هوش مصنوعی است که بر توانمندسازی رایانه ها برای شناسایی و پردازش اشیا تمرکز دارد. در تصاویر و فیلم ها به همان روشی که انسان ها انجام می دهند. تا همین اواخر ، بینایی رایانه فقط در ظرفیت محدود کار می کرد. اما به لطف پیشرفت در یادگیری عمیق ، این رشته در سال های اخیر توانسته است جهش های بزرگی داشته باشد و اکنون صنایع مختلف را به سرعت متحول می کند!
 اعتبار:/U/DEADBUILTIN Consolia-comic.com
اعتبار:/U/DEADBUILTIN Consolia-comic.com CV به سرعت در حال حرکت است به طوری که ما عملا در یک سال گذشته تنها یک دهه تغییر داشته ایم ، با بیش از 45000 مقاله در حال چاپ و بسیاری از مدل های هیولا توسط شرکت های بزرگ فناوری مانند OpenAI (به عنوان مثال iGPT [18] و CLIP [10]) و Google (به عنوان مثال ViT-G/14 [19]) منتشر می شوند! پیگیری این زمینه برای همه یک چالش است!
در این پست ، می توانید خلاصه کنفرانس CVPR ما را بخوانید. CVPR (بینایی رایانه و تشخیص الگو) یکی از همایش های پیشرو در زمینه بینایی رایانه است. امسال ، CVPR 83 کارگاه آموزشی ، 30 آموزش ، 50+ حامی و بیش از 1600 مقاله در 12 جلسه (از 7093 مقاله با نرخ پذیرش 23 ~)) داشت.
گرایش های اخیر
در CVPR 2021 ، زمینه های فرعی مختلف CV پیشرفت های امیدوار کننده ای را نشان داده اند. در حالی که برخی از موضوعات ، از جمله تقسیم بندی و طبقه بندی اشیاء ، در چند سال گذشته در مرکز توجه قرار گرفته اند ، موضوعات جدیدی به تازگی پدیدار شده و در سال 2021 به مرکزیت رسیده است. خلاصه ما بر این موضوعات متمرکز است:
ما همچنین مطالب خود را به اشتراک می گذاریم بینش در مورد دو صنعتی که CV در آنها مهم است:
یادگیری با مثالهای خصمانه مرور کلی
یادگیری عمیق و بینایی رایانه ای سیستم ها در کارهای مختلف موفق بوده اند اما نواقص خود را دارند. یکی از مواردی که اخیراً توجه جامعه تحقیقاتی را به خود جلب کرده است ، حساسیت این سیستم ها به نمونه های مخالف است. یک مثال خصمانه ، یک تصویر پر سر و صدا است که برای فریب سیستم به پیش بینی اشتباه طراحی شده است [1]. برای استقرار این سیستم ها در دنیای واقعی ، ضروری است که آنها بتوانند این نمونه ها را تشخیص دهند. برای این منظور ، آثار اخیر با استفاده از مثالهای خصمانه در فرایند آموزش ، امکان تقویت این سیستمها در برابر حملات خصمانه را بررسی می کنند.
مزایا و معایب یادگیری با مثالهای خصمانه
: روشهای متداول یادگیری عمیق ، هر نمونه آموزشی را در مجموعه داده به طور مساوی ، صرف نظر از درستی برچسب ، وزن می کند. این می تواند روند یادگیری را از مسیر خارج کند ، به خصوص اگر برچسب ها حاوی نویز باشند. از طریق یادگیری متقابل ، قابلیت اطمینان هر نمونه را می توان بر اساس پایداری برچسب پیش بینی شده آن هنگام افزودن سطوح مختلف نویز برآورد کرد. این مدل را قادر می سازد تا نمونه هایی را که در برابر سر و صدا مقاوم تر هستند ، شناسایی کرده و بر آنها تمرکز کند و در نتیجه حساسیت آن را به نمونه های مخالف کاهش دهد. علاوه بر این ، نشان داده شده است که نمونه های متخاصم در رژیم های آموزشی از معیارهای وظایف استاندارد مانند طبقه بندی و تشخیص اشیا پیشی گرفته است. این در تنظیمات نیمه تحت نظارت مفید است ، به عنوان مثال ، هنگامی که تعداد محدودی اطلاعات برچسب گذاری شده وجود داشته باشد.
معایب: آموزش متقابل شامل تنظیم پارامتر "epsilon" است که میزان نویز را کنترل می کندبه هر نمونه اضافه می شود "epsilon" که بیش از حد بالا است ممکن است مانع روند یادگیری شود. علاوه بر این ، آزمایشات انجام شده در [2] نشان می دهد که با در دسترس بودن مجموعه داده های بزرگ دارای برچسب ، عملکرد تکنیک های یادگیری تحت نظارت با تکنیک های آموزش خصمانه مطابقت دارد و مزایای آموزش خصومت را کمتر عمیق می کند.
حالت- هنر یادگیری با مثالهای متخاصم
SENTRY: این روش از مثالهای مخالف در زمینه آموزش یادگیری استفاده می کند. یادگیری انتقالی زمینه ای برای یادگیری ماشین است که در آن یک مدل آموزش داده شده بر روی توزیع منبع ، به طور دقیق تنظیم شده و بر اساس توزیع هدف متفاوت ارزیابی می شود. در میان توزیع هدف ، SENTRY به مساوی وزن برابر اختصاص داده شده برای همه نمونه ها می پردازد. با استفاده از روش "سازگاری پیش بینی" ، موارد هدف قابل اعتماد را شناسایی می کند. در این روش ، اطمینان پیش بینی مدل در موارد هدف بسیار سازگار که قابل اعتماد تلقی می شوند ، افزایش می یابد. به طور خاص ، یک نمونه ، همراه با چندین نسخه تقویت شده خود ، به مجموعه ای از مدل ها داده می شود. پیش بینی های هر مدل از نظر ثبات ارزیابی می شود. اگر مدلهای بیشتری در پیش بینی های خود سازگار باشند ، نمونه مورد نظر قابل اعتماد است ، بنابراین باید از آن برای به حداقل رساندن اتروپی استفاده کرد. اگر پیش بینی ها ناسازگار باشند ، نمونه مورد نظر قابل اعتماد نیست و بنابراین ، باید نادیده گرفته شود. با پیروی از این روش ، SENTRY به SOTA در DomainNet [3] دست می یابد که یک مجموعه داده استاندارد برای ارزیابی مدلها در مورد قابلیتهای یادگیری انتقال آنها است.
 مروری بر مدل SENTRY.
مروری بر مدل SENTRY. AdvProp: نشان دادن نمونه های خصمانه در آموزش نشان داده است که عملکرد مدل را بهبود می بخشد و منجر به ویژگی هایی می شود که بیشتر با تفسیر انسانی هم خوانی دارد [4]. این کار مدلهای آموزشی مشترک را بر روی تصاویر تمیز و مخالف بررسی می کند. کارهای قبلی مدل های پیش آموزش را در مورد نمونه های مخالف و سپس تنظیم دقیق روی تصاویر تمیز را بررسی می کند. در حالی که این امر عملکرد طبقه بندی را بهبود می بخشد ، مدل مستعد "فراموشی فاجعه بار" می شود ، جایی که یک مدل ویژگی هایی را که در مرحله قبل از آموزش آموخته است (در مورد تغییر دامنه) فراموش می کند. برای رسیدگی به این مسئله ، لایه های نرمال سازی دسته ای کمکی (BN) برای عادی سازی نمونه های مخالف پیشنهاد شده است. از طرف دیگر ، از لایه های معمولی BN برای عادی سازی تصاویر تمیز استفاده می شود. این به لایه های عادی اجازه می دهد تا بر اساس توزیع های مختلف نمونه های تمیز و مخالف رفتار متفاوتی داشته باشند. در طول استنتاج ، لایه های کمکی BN ریخته می شوند و لایه های معمولی BN برای پیش بینی استفاده می شود. این رژیم آموزشی همراه با EfficientNet به عنوان معماری ستون فقرات ، به عملکرد برتر SOTA 1 در دقت طبقه بندی ImageNet دست می یابد. علاوه بر این ، AdvProp به عملکرد SOTA در نسخه های دشوارتر ImageNet: ImageNet-a ، ImageNet-c و Stylized ImageNet دست می یابد. علاوه بر این ، شامل مثالهای مخالف در آموزش نیز SOTA را در تشخیص شی [5] به دست می آورد.
 مقایسه بین BN سنتی در مقابل BN کمکی.
مقایسه بین BN سنتی در مقابل BN کمکی. یادگیری خودآزمایی و متضاد یادگیری
یادگیری عمیق به داده های دارای برچسب تمیز نیاز دارد که بدست آوردن آنها برای بسیاری از برنامه ها دشوار است. حاشیه نویسی حجم زیادی از داده ها مستلزم نیروی انسانی شدید است که زمان بر و گران است. علاوه بر این ، توزیع داده ها همیشه در دنیای واقعی تغییر می کند و این بدان معناست که مدلها باید دائماً در مورد داده های در حال تغییر آموزش ببینند. روشهای خود نظارتی با استفاده از منابع فراوان داده های بدون برچسب خام برای آموزش مدلها ، برخی از این چالشها را برطرف می کند. که دردر این سناریو ، نظارت توسط خود داده ها (نه حاشیه نویسی های انسانی) ارائه می شود و هدف انجام یک کار بهانه است. وظایف بهانه اغلب اکتشافی هستند (به عنوان مثال ، پیش بینی چرخش) که در آن هر دو ورودی و خروجی از داده های بدون برچسب گرفته می شوند. هدف از تعریف یک وظیفه بهانه این است که مدل ها بتوانند ویژگی های مربوطه را یاد بگیرند که بعداً می توانند برای کارهای پایین دست استفاده شوند (که معمولاً حاشیه نویسی در دسترس هستند). یادگیری خود سرپرستی در سال 2020 هنگامی محبوبیت بیشتری پیدا کرد که سرانجام با عملکرد روشهای کاملاً تحت نظارت شروع به کار کرد. یکی از تکنیک های خاص یادگیری متضاد (CL) است.
CL از یک ایده قدیمی [6] الهام گرفته شده است که موارد مشابه باید در فضای تعبیه شده نزدیک بمانند ، در حالی که موارد غیرمتعارف باید با هم فاصله داشته باشند. برای پیاده سازی این ، CL جفت نمونه تشکیل می دهد. برای یک نمونه معین ، یک جفت مثبت با استفاده از مورد نمونه برداری شده و یک نسخه تقویت شده از آن ایجاد می شود. به طور مشابه ، یک جفت منفی با استفاده از یک مورد و یک مورد متفاوت ایجاد می شود. سپس ، ویژگی ها به گونه ای آموخته می شوند که جفت های مثبت در فضای تعبیه شده نزدیک هستند در حالی که جفت های منفی با هم فاصله زیادی دارند. این اجازه می دهد تا اقلام مشابه در فضای تعبیه شده در کنار هم قرار گیرند. مراکز خوشه ای می توانند معنای معنایی یا کلاس شی را نشان دهند. از آنجا که از برچسب ها استفاده نمی شود ، CL می تواند از فراوانی داده های بدون برچسب خام استفاده کند.
مزایا و معایب یادگیری خود سرپرستی و متقابل
مزایا: یادگیری خود سرپرستی یک داده است الگوی یادگیری کارآمد روشهای یادگیری تحت نظارت به مدلها می آموزد که در یک کار خاص خوب عمل کنند. از سوی دیگر ، یادگیری خود سرپرستی به شما امکان می دهد تا موارد کلی را بیاموزید که برای حل یک کار خاص تخصصی ندارند ، بلکه آمارهای غنی تری را برای انواع کارهای پایین دستی در بر می گیرد. از بین همه روشهای تحت نظارت خود ، استفاده از CL کیفیت ویژگی های استخراج شده را بیشتر می کند. ماهیت داده کارآمد یادگیری تحت نظارت ، آن را برای برنامه های کاربردی آموزش یادگیری مطلوب می کند.
معایب: بسیاری از موفقیت های یادگیری تحت نظارت خود را می توان به بزرگنمایی های تصویری با دقت انتخاب شده مانند بزرگنمایی ، محو شدن و برش نسبت داد. به بنابراین ، انتخاب مجموعه مناسب و میزان تقویت برای یک کار خاص می تواند یک فرآیند چالش برانگیز باشد. علاوه بر این ، CL ممکن است مدل را گمراه کند تا بین دو تصویر حاوی یک شیء یکسان تمایز قائل شود. به عنوان مثال ، برای تصویری از اسب ، برای ایجاد جفت منفی ، CL ممکن است تصویر دیگری را انتخاب کند که شامل اسب است. در این مورد ، آنچه مدل به عنوان یک جفت منفی در نظر می گیرد ، در واقع یک جفت مثبت است. یادگیری ساده نمایندگی سیامی: چارچوب شبکه سیامی معماری است که در یادگیری خود سرپرستی محبوبیت یافته است. بر خلاف CL که جفت های مثبت و منفی ایجاد می کند ، این چارچوب فقط شباهت بین بزرگنمایی یک تصویر را به حداکثر می رساند ، که به یادگیری نمایش های مفید کمک می کند. کارهای موازی در یادگیری خود سرپرستی از تلفات متضاد استفاده می کنند و موفقیت این آثار متکی به (i) استفاده از جفت های منفی [7] ، (ii) اندازه دسته ، و (iii) رمزگذارهای حرکت [8] است. SimSiam ، با این حال ، به این عوامل تکیه نمی کند ، و در انتخاب آنها قوی تر می شودهایپر پارامترها علاوه بر این ، SimSiam از تکنیک "stop-gradient" برای جلوگیری از سقوط ویژگی استفاده می کند. فروپاشی ویژگی پدیده ای است که در آن یک مدل میانبر را برای به حداقل رساندن عملکرد هدف بدون یادگیری نمایش های مفید یاد می گیرد. در نتیجه ، ویژگی های آموخته شده قابل تعمیم نیستند. با اجتناب از فروپاشی ویژگی ، SimSiam به نتایج رقابتی در ImageNet و کارهای بعدی آن مانند تشخیص شیء COCO و تقسیم بندی نمونه می رسد.
 معماری سیم سیم. معماری ستون فقرات مورد استفاده ، ترانسفورماتور است [10] ، که نشان داده شده است که برتر از شبکه های کانولوشن است. [اگر علاقمند به کسب اطلاعات بیشتر در مورد DINO هستید ، این ویدیو را ببینید]. با استفاده از ترانسفورماتور + چارچوب DINO ، SOTA برای کارهای طبقه بندی تصویر بهبود یافته است. DINO را می توان در برنامه هایی مانند تشخیص کپی و بازیابی تصویر اعمال کرد. با توجه به تصویر پرس و جو ، همه نسخه های ممکن از آن تصویر در اسرع وقت بازیابی می شود. علاوه بر این ، DINO قابلیت تقسیم بندی را به صورت رایگان ارائه می دهد. مشخص شده است که ویژگیهای آموخته شده در DINO در مقایسه با روشهای تحت نظارت در ایجاد نقشه برجسته بهتر است. سرانجام ، با آستانه گذاری دقیق ، DINO می تواند خارج از جعبه برای تقسیم بندی شیء ویدیویی در هر فریم بدون آموزش ثبات زمانی استفاده شود.
معماری سیم سیم. معماری ستون فقرات مورد استفاده ، ترانسفورماتور است [10] ، که نشان داده شده است که برتر از شبکه های کانولوشن است. [اگر علاقمند به کسب اطلاعات بیشتر در مورد DINO هستید ، این ویدیو را ببینید]. با استفاده از ترانسفورماتور + چارچوب DINO ، SOTA برای کارهای طبقه بندی تصویر بهبود یافته است. DINO را می توان در برنامه هایی مانند تشخیص کپی و بازیابی تصویر اعمال کرد. با توجه به تصویر پرس و جو ، همه نسخه های ممکن از آن تصویر در اسرع وقت بازیابی می شود. علاوه بر این ، DINO قابلیت تقسیم بندی را به صورت رایگان ارائه می دهد. مشخص شده است که ویژگیهای آموخته شده در DINO در مقایسه با روشهای تحت نظارت در ایجاد نقشه برجسته بهتر است. سرانجام ، با آستانه گذاری دقیق ، DINO می تواند خارج از جعبه برای تقسیم بندی شیء ویدیویی در هر فریم بدون آموزش ثبات زمانی استفاده شود.  نتایج بخش بندی از روشهای تحت نظارت در مقابل DINO.
نتایج بخش بندی از روشهای تحت نظارت در مقابل DINO. مروری بر مدلهای زبان بینایی
Vision-Language (VL) شامل سیستمهای آموزشی است که درک مشترکی از روشهای تصویر و متن دارند. VL شبیه نحوه تعامل انسانها با جهان است. بینایی بخش بزرگی از نحوه درک انسانها از جهان است و زبان بخش بزرگی از نحوه ارتباط انسانها است. مدلهای VL یک فضای تعبیه مشترک با روشهای مختلف داده را یاد می گیرند. برای آموزش ، از جفت های تصویر و متن استفاده می شود ، جایی که متن معمولاً تصویر را توصیف می کند. بیشتر کارهای اخیر در این زمینه از آموزش مبتنی بر ترانسفورماتور برای نظارت بر خود برای استخراج ویژگی ها از داده ها استفاده می کند. در یک نکته مماس ، از جفت های ویدئویی-متنی برای یادگیری تصاویر غنی و متراکم استفاده شده است. با این حال ، هنوز یک زمینه نوپا با پتانسیل بالا است. به علاوه بر این ، تعداد زیادی از داده ها ، مانند فیلم های YouTube و حاشیه نویسی های خودکار ، می توانند برای آموزش این سیستم ها استفاده شوند. مشابه یادگیری تحت نظارت خود ، ویژگی های آموخته شده جهانی هستند و می توانند برای چندین وظیفه پایین دست مانند
علاوه بر این ، مدلهای VL را می توان برای یادگیری ویژگیهای بصری بهتر و برای تقویت نمایش زبان به عنوان
پیشرفته ترین مدلهای زبان دید
< p> VinVL: بازبینی نمایندگی های بصری در مدل های زبان دید: VinVL بر روی نمایش های بصری برای کارهای VL بهبود می یابد. مدلهای VL به طور کلی دارای یک مدل آشکارساز شی هستندو مدل استخراج زبان به دنبال یک مدل تلفیقی. مدل تلفیقی مسئول ادغام تعبیه های بصری و زبانی است. مدلهای قبلی VL عمدتا بر بهبود مدل همجوشی بینایی-زبان [15] متمرکز بوده اند در حالی که مدل تشخیص شیء را دست نخورده نگه داشته است. VinVL نشان می دهد که ویژگی های بصری در مدل های VL بسیار مهم هستند و یک مدل تشخیص شی بهبود یافته را پیشنهاد می کند. مدل تشخیص شیء ، جعبه های محدود کننده ای را تشخیص می دهد که تقریباً تمام مناطق معنایی تصویر را پوشش می دهند ، در مقابل جعبه های مرزی سنتی که فقط اشیاء مهم را پوشش می دهند. سرانجام ، ویژگی های بصری با جاسازی زبان از طریق ترانسفورماتور ادغام می شوند [16]. پس از پیش آموزش روی مجموعه داده های متعدد ، VinVL برای چندین وظیفه پایین دستی (VQA ، IC و غیره) مجدداً راه اندازی می شود و عملکرد SOTA را در هفت معیار عمومی به دست می آورد. مزایای عملکرد را می توان به بهبود مدل تشخیص شی نسبت داد. مقایسه جعبه های پیش بینی با استفاده از مدل استاندارد تشخیص شیء (چپ) در مقابل مدل تشخیص بهبود یافته VinVL (راست). و اندازه داده های آموزش با این حال ، در سناریوهای دنیای واقعی ، حجم زیادی از داده های دارای برچسب معمولاً گران هستند یا به آسانی در دسترس نیستند. این موضوع با در نظر گرفتن کلاسهای بصری که نیاز به حاشیه نویسی بر اساس دانش متخصص دارند (به عنوان مثال ، تصویربرداری پزشکی) ، کلاسهایی که به ندرت اتفاق می افتد ، یا کارهایی که برچسب زدن به تلاش زیادی نیاز دارد (به عنوان مثال ، تقسیم بندی تصویر) ، حتی این مسئله نیز شدیدتر می شود. در دهه گذشته ، زمینه های مختلف تحقیقاتی برای حل این چالش ها پدید آمده است. زمینه هایی مانند یادگیری تحت نظارت ضعیف ، یادگیری انتقال یافته و خود/نیمه تحت نظارت سعی در غلبه بر این چالش ها با امکان مدل های ML برای یادگیری از نظارت محدود ، ضعیف یا پر سر و صدا دارند. از آنجا که خود/نیمه تحت نظارت در بالا توضیح داده شده است ، در اینجا ما عمدتا بر یادگیری با نظارت ضعیف و انتقال یادگیری تمرکز می کنیم.
مقایسه جعبه های پیش بینی با استفاده از مدل استاندارد تشخیص شیء (چپ) در مقابل مدل تشخیص بهبود یافته VinVL (راست). و اندازه داده های آموزش با این حال ، در سناریوهای دنیای واقعی ، حجم زیادی از داده های دارای برچسب معمولاً گران هستند یا به آسانی در دسترس نیستند. این موضوع با در نظر گرفتن کلاسهای بصری که نیاز به حاشیه نویسی بر اساس دانش متخصص دارند (به عنوان مثال ، تصویربرداری پزشکی) ، کلاسهایی که به ندرت اتفاق می افتد ، یا کارهایی که برچسب زدن به تلاش زیادی نیاز دارد (به عنوان مثال ، تقسیم بندی تصویر) ، حتی این مسئله نیز شدیدتر می شود. در دهه گذشته ، زمینه های مختلف تحقیقاتی برای حل این چالش ها پدید آمده است. زمینه هایی مانند یادگیری تحت نظارت ضعیف ، یادگیری انتقال یافته و خود/نیمه تحت نظارت سعی در غلبه بر این چالش ها با امکان مدل های ML برای یادگیری از نظارت محدود ، ضعیف یا پر سر و صدا دارند. از آنجا که خود/نیمه تحت نظارت در بالا توضیح داده شده است ، در اینجا ما عمدتا بر یادگیری با نظارت ضعیف و انتقال یادگیری تمرکز می کنیم. مزایا و معایب یادگیری با داده های محدود
مزایا: یادگیری با نظارت ضعیف و انتقال یادگیری به کاهش میزان داده های برچسب گذاری شده برای آموزش مدل های CV و در نتیجه افزایش کاربرد و پذیرش این مدل ها در صنعت کمک می کند. یادگیری با نظارت ضعیف همچنین می تواند به مدل ها کمک کند تا در حضور برچسب های پر سر و صدا عملکرد بهتری داشته باشند ، که اغلب در محیط های واقعی مشاهده می شود. علاوه بر این ، روشهای یادگیری انتقال مبتنی بر نمونه را می توان برای غلبه بر چالش های عدم تعادل کلاس (به عنوان مثال ، توزیع طولانی مدت جهان بصری [17]) که به طور طبیعی با مجموعه داده های دنیای واقعی به وجود می آید ، استفاده کرد.
معایب: یادگیری با نظارت ضعیف و یادگیری انتقال هر دو زمینه های نسبتاً جدیدی هستند و هنوز قبل از استفاده در صنعت به زمان نیاز دارند. این روشها اغلب بر اساس معیارهای جمع آوری شده از محیط های کنترل شده توسعه و ارزیابی می شوند و بنابراین عملکرد آنها معمولاً وقتی در محیط های واقعی آزمایش می شوند کاهش می یابد. علاوه بر این ، بیشتر مقالات جالب در این زمینه ها بر اساس مفروضاتی است که در محیط های تحقیق وجود دارد ، اما نه لزوماً در محیط های واقعی. مراقب مفروضات ضمنی و صریح در این مقاله ها هنگام استفاده از آنها برای حل مشکلات دنیای واقعی باشید.
پیشرفته ترین روش یادگیری با داده های محدود
WyPR: تشخیص نقطه با نظارت ضعیف: WyPR یک ابر نقطه ای را به عنوان ورودی می گیرد و به طور مشترک به تقسیم بندی ، تولید پیشنهاد و تشخیص می پردازد. پرداختن مشترک به این وظایف چندین مزیت دارد از جمله:
WyPR با استفاده از روشهای چند مرحله ای (MIL) و تکنیک های خودآموزی با ضررهای سازگاری اضافی که در وظایف و تحولات تعریف شده است ، آموزش می بیند. WyPR نسبت به روش های تقسیم بندی قبلی 6.3٪ mIoU در داده های ScanNet عملکرد بهتری دارد. به طور مشابه ، از روش های پیشنهادی قبلی برای ایجاد و تشخیص پیشنهاد در ScanNet پیشی می گیرد.
 مروری بر چارچوب WyPR.
مروری بر چارچوب WyPR. DatasetGAN: DatasetGAN برای ایجاد داده های آموزشی واقع گرایانه-اعم از تصاویر و برچسب ها ، از شبکه های مخالف تولیدی (GANs) و یادگیری چند مرحله ای (زیر زمینه یادگیری انتقال) استفاده می کند. این روش بر اساس StyleGAN [20] ساخته شده است که جدیدترین مدل برای تولید تصاویر واقعی است. StyleGAN به طور پیش فرض فقط تصاویر ایجاد می کند. برای فعال کردن StyleGAN برای ایجاد برچسب (به عنوان مثال ، نقشه های تقسیم بندی معنایی) علاوه بر تصاویر ، آنها یک شاخه برچسب به بلوک سنتز در StyleGAN اضافه می کنند. شاخه برچسب تنها چند لایه پرسپترون چند لایه است که در این کار با 16 نمونه برچسب آموزش داده شده است. این مقاله نشان می دهد که این روش حتی با یک نمونه برچسب دار می تواند نتایج معقولی را به دست آورد و در صورت ارائه 30 نمونه برچسب دار ، عملکرد روشهای کاملاً تحت نظارت را بدست می آورد. علاوه بر این ، نویسندگان نشان می دهند که می توان از همان ایده برای تولید فیلم های مصنوعی با برچسب [21] استفاده کرد.
 تصویرسازی مراحل مختلف در DatasetGAN.
تصویرسازی مراحل مختلف در DatasetGAN. جلسات جالب-خرده فروشی
از بررسی خودکار تا توصیه محصول ، CV به شرکت های خرده فروشی کمک کرده است تا در گذشته گام های مهمی بردارند. چند سال. در زیر چند نمونه از شرکت ها و استارتاپ هایی که از CV برای افزایش تجربه خرده فروشی خود استفاده می کنند آورده شده است:
جلسات جالب-رانندگی مستقل
وسایل نقلیه خودران در مرکز توجه قرار گرفته اند چند سال. در چندین شرکت و استارتاپ سرمایه گذاری شده استخودروهای خودران مانند گوگل ، تسلا ، اوبر ، تویوتا و واآبی به چند مورد اشاره می کنند. در حالی که اصول اساسی دستیابی به سطح 5 خودمختاری ، یعنی زمانی که خودرو بدون دخالت انسان حرکت می کند ، ثابت است ، رهبران این فضا نظرات متفاوتی در مورد عملکرد بهتر سنسورها دارند. خودروهای خودران از سنسورهای گسترده ای برای بدست آوردن اطلاعات در مورد محیط اطراف خود استفاده می کنند. این داده ها سپس به مدل های CV داده می شوند تا پیش بینی هایی را که برای رانندگی مستقل لازم است بدست آورند. برخی از شرکتها سنسورهای دوربین را به عنوان استاندارد طلا در نظر گرفته اند در حالی که برخی دیگر ترجیح می دهند ترکیبی از سنسورهای دوربین و رادار باشد. پیش بینی کنید این تیم به طور تجربی مزایای استفاده از سنسورهای دوربین را نسبت به رادار نشان داد. ایلان ماسک ، مدیرعامل تسلا حتی در این مورد توییت کرد! علاوه بر این ، تیم استدلال می کند که سنسورهای دوربین ارزان تر از رادار هستند و از نظر تولید در مقیاس مقرون به صرفه تر هستند. در مقایسه با رقبای خود ، تسلا در حال حاضر هزاران اتومبیل خودران در خیابان دارد. این به آنها امکان می دهد داده های زمان واقعی شرایط رانندگی منحصر به فرد را که در طول آموزش لحاظ نشده اند ، جمع آوری کنند. به همین منظور ، تسلا دارای زیرساختی به نام "ناوگان" است و تنها هدف آن جمع آوری داده ها در مورد شرایط مختلف رانندگی از نقاط مختلف جهان است. تسلا با ایدئولوژی "داده های بزرگ = خلبان خودکار حل شده است" ، پیشگام تحقیقات و توسعه در صنعت رانندگی خودران است. مقالات جالب
بینایی رایانه ای
بینایی رایانه ای
آیا ترانسفورماتورها جایگزین CNN ها در بینایی رایانه ای می شوند؟
در کمتر از 5 دقیقه ، می دانید که چگونه می توان معماری ترانسفورماتور را با یک مقاله جدید در بینایی رایانه به کار برد. به نام Swin Transformer
 تصویر نویسنده.
تصویر نویسنده. این مقاله به احتمال زیاد نسل بعدی شبکه های عصبی برای همه برنامه های بینایی رایانه است: معماری ترانسفورماتور. مطمئناً قبلاً در مورد این معماری در زمینه پردازش زبان طبیعی یا NLP ، عمدتا با GPT3 که در سال 2020 سر و صدای زیادی ایجاد کرده است ، شنیده اید. ترانسفورماتورها را می توان به عنوان ستون فقرات عمومی برای بسیاری از برنامه های مختلف و نه تنها NLP استفاده کرد. به در عرض چند دقیقه ، می دانید که چگونه می توان معماری ترانسفورماتور را با یک مقاله جدید به نام Swin Transformer توسط Ze Lio و همکاران در بینایی رایانه اعمال کرد. از Microsoft Research [1].
این مقاله ممکن است کمتر از حالت معمول درخشان باشد زیرا نتایج واقعی یک برنامه دقیق را نشان نمی دهد. در عوض ، محققان [1] نشان دادند که چگونه می توان معماری ترانسفورماتورها را از ورودی های متن به تصاویر تطبیق داد و از شبکه های عصبی پیچیده ای از بینایی رایانه پیشی گرفت ، که به نظر من از بهبود کمی جزئی بسیار هیجان انگیز است. و البته ، آنها کد [2] را برای شما ارائه می دهند تا خودتان پیاده سازی کنید! پیوند در منابع زیر است.
چرا از ترانسفورماتورها در شبکه های CNN استفاده کنیم؟
اما چرا ما سعی می کنیم شبکه های عصبی متحرک (CNN) را برای برنامه های بینایی رایانه جایگزین کنیم؟ این به این دلیل است که ترانسفورماتورها می توانند از حافظه بسیار بیشتری استفاده کنند و در مورد کارهای پیچیده بسیار قوی تر هستند. این البته با توجه به این واقعیت است که شما داده هایی برای آموزش آن دارید. ترانسفورماتورها همچنین از مکانیزم توجه معرفی شده در مقاله 2017 استفاده می کنند توجه فقط به آن نیاز دارید [3]. توجه به معماری ترانسفورماتور اجازه می دهد تا به صورت موازی محاسبه شود.
 فرآیند توجه در NLP تصویر توسط Davide Coccomini با اجازه بازنشر می شود. شبکه های CNN بسیار محلی تر هستند و از فیلترهای کوچک برای فشرده سازی اطلاعات به سمت پاسخ کلی استفاده می کنند.
در حالی که این معماری برای کارهای طبقه بندی عمومی قدرتمند است ، اما اطلاعات مکانی لازم برای بسیاری از وظایف مانند تشخیص نمونه را ندارد. این به این دلیل است که پیچیدگی ها روابط پیکسل های فاصله دار را در نظر نمی گیرند.
فرآیند توجه در NLP تصویر توسط Davide Coccomini با اجازه بازنشر می شود. شبکه های CNN بسیار محلی تر هستند و از فیلترهای کوچک برای فشرده سازی اطلاعات به سمت پاسخ کلی استفاده می کنند.
در حالی که این معماری برای کارهای طبقه بندی عمومی قدرتمند است ، اما اطلاعات مکانی لازم برای بسیاری از وظایف مانند تشخیص نمونه را ندارد. این به این دلیل است که پیچیدگی ها روابط پیکسل های فاصله دار را در نظر نمی گیرند. 
 مثال توجه به خود در Transformers برای NLP (چپ) و دید رایانه (راست). تصویر توسط نویسنده. برای معرفی سریع مفهوم توجه ، بیایید یک مثال ساده NLP را ارسال کنیم که یک جمله را برای ترجمه آن به یک شبکه ترانسفورماتور ارسال می کند. در این مورد ، توجه اساساً اندازه گیری نحوه ارتباط هر کلمه در جمله ورودی با هر کلمه در جمله ترجمه خروجی است. به طور مشابه ، چیزی وجود دارد که ما آن را توجه به خود می نامیم و می تواند به عنوان اندازه گیری تأثیر یک کلمه خاص بر همه کلمات دیگر یک جمله تلقی شود. این فرایند مشابه را می توان برای تصاویر محاسبه کننده توجه اعمال کردتکه های تصاویر و روابط آنها با یکدیگر ، همانطور که در مقاله بیشتر بحث خواهیم کرد.
مثال توجه به خود در Transformers برای NLP (چپ) و دید رایانه (راست). تصویر توسط نویسنده. برای معرفی سریع مفهوم توجه ، بیایید یک مثال ساده NLP را ارسال کنیم که یک جمله را برای ترجمه آن به یک شبکه ترانسفورماتور ارسال می کند. در این مورد ، توجه اساساً اندازه گیری نحوه ارتباط هر کلمه در جمله ورودی با هر کلمه در جمله ترجمه خروجی است. به طور مشابه ، چیزی وجود دارد که ما آن را توجه به خود می نامیم و می تواند به عنوان اندازه گیری تأثیر یک کلمه خاص بر همه کلمات دیگر یک جمله تلقی شود. این فرایند مشابه را می توان برای تصاویر محاسبه کننده توجه اعمال کردتکه های تصاویر و روابط آنها با یکدیگر ، همانطور که در مقاله بیشتر بحث خواهیم کرد. 
ترانسفورماتورها در بینایی کامپیوتر
اکنون که می دانیم ترانسفورماتورها بسیار جالب هستند ، هنوز مشکلی در برنامه های بینایی رایانه وجود دارد. در واقع ، درست مانند ضرب المثل رایج "یک تصویر هزار کلمه ارزش دارد" ، تصاویر حاوی اطلاعات بسیار بیشتری نسبت به جملات هستند ، بنابراین ما باید معماری ترانسفورماتور اصلی را برای پردازش م imagesثر تصاویر تطبیق دهیم. این مقاله در مورد این است.
 پیچیدگی ترانسفورماتورهای بینایی. تصویر توسط داوید کوکومینی با مجوز بازنشر می شود. بنابراین زمان محاسبه و نیازهای حافظه افزایش می یابد. در عوض ، محققان این پیچیدگی محاسباتی درجه دوم را با پیچیدگی محاسباتی خطی به اندازه تصویر جایگزین کردند.
پیچیدگی ترانسفورماتورهای بینایی. تصویر توسط داوید کوکومینی با مجوز بازنشر می شود. بنابراین زمان محاسبه و نیازهای حافظه افزایش می یابد. در عوض ، محققان این پیچیدگی محاسباتی درجه دوم را با پیچیدگی محاسباتی خطی به اندازه تصویر جایگزین کردند.  اولین مرحله از معماری Swin Transformer ، نشانه گذاری تصویر. تصویر نویسنده.
اولین مرحله از معماری Swin Transformer ، نشانه گذاری تصویر. تصویر نویسنده. ترانسفورماتور Swin [1] [2]
روند دستیابی به این امر بسیار ساده است. در ابتدا ، مانند اکثر کارهای بینایی رایانه ، یک تصویر RGB به شبکه ارسال می شود. این تصویر به وصله تقسیم می شود و هر پچ به عنوان یک نشانه تلقی می شود. و ویژگی های این توکن ها مقادیر RGB خود پیکسل ها هستند. برای مقایسه با NLP ، می توانید این را به عنوان تصویر کلی جمله ببینید ، و هر پچ کلمات آن جمله است. توجه به خود بر روی هر پچ اعمال می شود ، که در اینجا به آن پنجره می گویند. سپس ، پنجره ها جابجا می شوند و در نتیجه پیکربندی پنجره جدیدی برای اعمال مجدد توجه به خود ایجاد می شود. این امکان ایجاد ارتباط بین پنجره ها را با حفظ بازده محاسبه این معماری پنجره دار فراهم می کند. این امر در مقایسه با شبکه های عصبی پیچشی بسیار جالب است زیرا اجازه می دهد روابط پیکسل های دوربرد ظاهر شود.
 توجه به خود در پنجره ها اعمال می شود. تصویر نویسنده.
توجه به خود در پنجره ها اعمال می شود. تصویر نویسنده. این فقط برای مرحله اول بود. مرحله دوم بسیار مشابه است اما ویژگی های هر گروه دو نفره را با دو تکه مجاور به هم پیوند می دهد و وضوح تصویر را تا دو برابر کاهش می دهد. این روش در مراحل 3 و 4 دو بار تکرار می شود و همان وضوح نقشه ویژگی را ایجاد می کند ، مانند شبکه های معمولی کانولوشن مانند ResNets و VGG. محصولات خوب ، بله و خیر. تصویر نویسنده.
قدرت پیچیدگی در این است که فیلترها از وزن های ثابت در سطح جهانی استفاده می کنند و ویژگی ترجمه-تغییر ناپذیری پیچیدگی را امکان پذیر می کند و آن را به یک تعمیم قدرتمند تبدیل می کند. در توجه به خود ، وزن ها در سطح جهانی ثابت نیستند. در عوض ، آنها بر خود زمینه محلی تکیه می کنند. بنابراین ، توجه به خود هر پیکسل را در نظر می گیرد ، بلکه رابطه آن را با پیکسل های دیگر در نظر می گیرد.
 تغییر پنجره مشکل رابطه طولانی مدت. تصویر توسط نویسنده.
تغییر پنجره مشکل رابطه طولانی مدت. تصویر توسط نویسنده. همچنین ، تکنیک پنجره تغییر یافته آنها امکان نمایش پیکسل های دوربرد را فراهم می کند. متأسفانه ، این روابط طولانی مدت تنها با پنجره های مجاور ظاهر می شود. بنابراین ، از دست دادن روابط بسیار دور ، نشان می دهد که هنوز جایی برای بهبود معماری ترانسفورماتور در مورد بینایی رایانه وجود دارد.
نتیجه گیری
همانطور که در مقاله بیان شده است. :
و من کاملاً موافقم. من فکر می کنم استفاده از معماری مشابه برای بینایی NLP و رایانه می تواند روند تحقیق را به میزان قابل توجهی تسریع کند. البته ، ترانسفورماتورها هنوز به شدت وابسته به داده هستند و هیچ کس نمی تواند بگوید آیا آینده NLP یا دید رایانه ای خواهد بود یا خیر. با این حال ، بدون شک این یک گام مهم برای هر دو زمینه است!
امیدوارم این مقاله بتواند شما را با ترانسفورماتورها و نحوه کاربرد آنها در برنامه های بینایی رایانه آشنا کند.
ممنون که خواندید! مقالات بیشتری مانند این را در وبلاگ من بیابید و آنها را قبل از به اشتراک گذاری در Medium بخوانید!
اگر از کارهای من خوشتان می آید و می خواهید با هوش مصنوعی به روز باشید ، قطعاً باید مرا در وب سایت من دنبال کنید سایر حسابهای رسانه های اجتماعی (LinkedIn ، Twitter) و مشترک خبرنامه هوش مصنوعی هفتگی من شوید!
برای حمایت از من:
مراجع
[1] Liu ، Z. et al.، 2021، "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" ، arXiv preprint https : //arxiv.org/abs/2103.14030v1
[2] Swin Transformer ، Lio ، Z. et al ، کد GitHub ، https://github.com/microsoft/Swin-Transformer
[3] واسوانی ، A. و همکاران ، 2017. "توجه تنها چیزی است که شما نیاز دارید" ، پیش چاپ arXiv https://arxiv.org/a bs/1706.03762.
بلوز پس از فارغ التحصیلی: 10 نکته برای گرایش اخیر علوم کامپیوتر
بلوز پس از فارغ التحصیلی: 10 نکته برای گرایش اخیر علوم کامپیوتر
روزی را که از دانشگاه فارغ التحصیل شدم ، دیروز به یاد دارم. در محاصره صدها دوست نزدیک ، خانواده و همسالان ، به سخنان رئیس دانشگاه ما گوش دادم تا او عظمت این مراسم را توصیف کند. این همان لحظه ای بود که من منتظرش بودم ... چهار سال گذشته بالاخره ارزشش را داشت.
به خاطر دارم که آنجا نشسته بودم و با انتظار مشتاقانه لبخند می زدم. من آماده بودم تا به دنیا ثابت کنم که چگونه می توانم در صنعت با پشتکار درخشش داشته باشم تا رویاهایی را که قبلاً ندیده بودم دنبال کنم.
 خودم در مراسم پیاده روی دانشگاه وبستر (مه 2018) ، جایی که پس از فارغ التحصیلی در دسامبر 2017 لیسانس علوم خود را در رشته کامپیوتر دریافت کردم.
خودم در مراسم پیاده روی دانشگاه وبستر (مه 2018) ، جایی که پس از فارغ التحصیلی در دسامبر 2017 لیسانس علوم خود را در رشته کامپیوتر دریافت کردم. شش ماه قبل از فارغ التحصیلی ، به یاد دارم که وقتم را با نمایشگاه های کاری ، قهوه و مصاحبه های متعدد پر می کردم. "فقط منتظر بمانید تا فارغ التحصیل شوید" هر استخدام کننده به من گفت ، "شما آینده امیدوار کننده ای در پیش دارید در این صنعت. فقط آنجا بمانید ما همیشه جایی برای استعدادهای جوان داریم. " نقطه. به نظر می رسد هر چیزی که در مورد صنعت خوانده ام حقیقت داشته باشد. توسعه دهندگان نرم افزار حرفه ای تقاضا داشتند و من مشتاق پیوستن به ردیف آنها بودم. >
به یاد دارم که یک هفته پس از فارغ التحصیلی به صندوق ورودی ایمیل خود خیره شده بودم و به شدت به نشانه ای از زندگی در مورد جستجوی کار امیدوار بودم. در هر ایمیل آمده است: "موقعیت تکمیل شد" ، "متشکرم که درخواست دادید" و "ما تصمیم داریم با متقاضی دیگری برویم." هر ایمیل رد کننده من را عمیق تر و عمیق تر از ایمیل قبلی می کند. چگونه ممکن است این اتفاق برای من بیفتد؟ به من گفته شد که مدرک تحصیلی من کلیدی است که بقیه آینده من را باز می کند ، اما 15… 16… 17 درخواست بعداً ، من به شغل تمام وقت نزدیک تر از آن 6 ماه قبل نبودم.
آینده ای که من فکر می کردم بسیار روشن است در مقابل من ناگهان بسیار دور از دسترس احساس می شود.
جستجوی شغل پس از فارغ التحصیلی یکی از سخت ترین و ناامید کننده ترین مواردی است که تا کنون در حرفه خود با آن روبرو شده ام. چگونه اینقدر بد فهمیدم که جستجوی کار من چگونه خواهد بود؟ شما می توانید شگفتی مرا تصور کنید وقتی شروع به گفتگو با دیگران در مورد تجربه شغل خود کردم ، اما متوجه شدم که تنها نیستم.
بین ملاقات های محلی ، باشگاه ها و سازمان ها ، من کاملاً شوکه شدم پیدا کنید چند نفر با مدرک (یا حداقل تجربه توسعه مناسب) در صنعت خدمات مشغول به کار بودند فقط به این دلیل که شغل آنها نیز مانند من با آنها بی رحمانه رفتار کرده است.
هر چند به ما یاد داده اند که چقدر مفید است حرفه ای در توسعه نرم افزار خواهد بود ، من احساس می کنم که ما فارغ التحصیلان خود را برای شرایطی که دنیای شغل در این روزها چگونه است آماده نمی کنیم. با تغییر دنیای اطراف مابه سرعت ، من معتقدم تجهیز دانش آموزان به نحوه برخورد با جستجوی شغلی به اندازه دانستن مهارت های فنی اهمیت دارد. فارغ التحصیلان دنیای توسعه نرم افزار ما به سادگی درک نمی کنیم که چگونه می توان از طریق تحصیلات دانشگاهی وارد این صنعت شد.
سه سال پیش فارغ التحصیل شدم بدون این که بدانم آینده من چگونه خواهد بود ، اما امروز می توانم با اطمینان بگویم که هستم یک توسعه دهنده نرم افزار حرفه ای با آینده ای روشن پیش رویم. من این مقاله را به امید دلجویی از کسانی که جستجوی شغلی آنها شبیه به کار من بود ، می نویسم و توصیه های ارزشمندی را که در مورد شغل پس از فارغ التحصیلی دریافت کردم ، به اشتراک می گذارم. این اطلاعات واقعاً حرفه من را بهتر کرد و امیدوارم این نکات نیز مانند من مفید واقع شود.
اکنون بدون هیچ گونه توضیح بیشتر ... در اینجا 10 راهنمایی برتر من برای فارغ التحصیلان اخیر کامپیوتر ، در جستجوی شغل ، آمده است. .

10 نکته برای کار- فارغ التحصیل علوم کامپیوتر شکار
در زیر هر نکته ، مقالات خارجی را قرار داده ام که در آن می توانید اطلاعات بیشتری در مورد موضوع پیدا کنید. نویسندگان و وب سایت ها باورهای شخصی من را منعکس نمی کنند ، اما من منابع آنها را برای تحقیقات بیشتر مرتبط و مفید می دانم. با خیال راحت از این پیوندها به عنوان سکوی پرش در تحقیقات خود استفاده کنید!
1. درک سخت ترین مانع شما کسب تجربه است.
همه توسعه دهندگان را می خواهند. خوب ، همه به توسعه دهندگان نیاز دارند. با این حال ، آیا اکثر مشاغل حاضرند برای کاهش سرعت و آموزش مهارت های مورد نیاز برای انجام کار وقت بگذارند؟ خیر. به همین دلیل است که کار کردن در خارج از دانشگاه می تواند بسیار دشوار باشد. هنگامی که برای اولین بار شروع به کار می کنید ، در معرض آسیب قرار خواهید گرفت. حتی اگر کارآموزی ، تجربه رهبری و ساعتهای داوطلبانه متعددی داشته باشید (مانند من). شرکت ها ارزیابی می کنند که چقدر طول می کشد تا شروع به بازگشت سرمایه خود کنند.
صبور باشید و درک کنید که هر محیط کاری برای یادگیری شما مناسب نخواهد بود. هرچند موقعیت هایی در آنجا وجود دارد. سخت بنگرید و کاملاً نگاه کنید ، آنها را پیدا خواهید کرد.
2. مطمئن شوید کد شما برای کارفرمایان بالقوه قابل مشاهده است.
این یکی از اولین توصیه هایی بود که در مورد جستجوی کارم دریافت کردم و ای کاش زودتر از آن استفاده می کردم. در دانشکده 3 دوره مختلف مختلف را گذراندم ، هر کدام یک اتصال دهنده به ضخامت 2 اینچ پر از کد و سیستم هایی که شخصاً ساخته بودم تولید می کرد. با وجود آن همه کار سخت ، هیچ یک از مصاحبه هایی که برای دیدن کارهایی که انجام داده بودم به دست نیاورده بودم زیرا مشاهده آنها در دسترس نبود!
Github و Bitbucket منابع باورنکردنی هستند که شما اگر قصد دارید در پایگاه های کد سطح شرکت مشارکت کنید ، باید از آن استفاده کنید. در حال متداول شدن درخواست های شغلی برای درخواست پیوندهای شخصی استمخازن کد تا استخدام کنندگان فنی بتوانند قبل از ایجاد مصاحبه مهارت های شما را مرور کنند. سرمایه گذاری در یادگیری در مورد این سیستم عامل مدیریت منبع کنترل. پشیمان نخواهید شد.
3. شروع به توسعه شبکه حرفه ای خود از طریق رسانه های اجتماعی کنید.
LinkedIn یک سایت حرفه ای شبکه های اجتماعی حرفه ای است که من از آن برای راحتی در خانه خود استفاده می کنم. بین ملاقات با متخصصان جدید ، تهیه قهوه با افرادی که من آنها را تحسین می کنم و خواندن مقالات مفید ، LinkedIn یک منبع عالی برای کسانی است که به دنبال پیشرفت حرفه ای هستند. همچنین ، این یک بستر مناسب برای جستجوی اولین شغل است.
اگر قبلاً حساب کاربری ایجاد نکرده اید ، به دنبال ایجاد یک پروفایل LinkedIn باشید و از منابع استخدام رایگان استفاده کنید. عضویت همچنین لازم به ذکر است که سایر بسترهای رسانه های اجتماعی ، مانند توییتر ، مملو از توسعه دهندگان نرم افزار است که دانش و تجربه خود را به اشتراک می گذارند. از این جوامع استفاده کنید و از مشارکت خودتان در آنها نترسید! همه باید از جایی شروع کنند.
4. از پیدا کردن یک سرباز نترسید.
همانطور که قبلاً اشاره کردم ، تعداد موقعیت های بیشتری نسبت به توسعه دهندگان برای پر کردن آنها وجود دارد. به همین دلیل ، شرکت ها زمان سختی را برای یافتن بهترین کاندیدای واجد شرایط دارند. همه ما می دانیم ، جایی که مشکلی وجود دارد ، باید پول به دست آورد. Cue ورود به صنعت استخدام فنی.
آژانس های استخدام فنی با ارائه خدمات به شرکت ها و ارائه استعدادهای بدون هزینه برای افراد استخدام شده ، به رفع این فاصله کمک کرده اند. با یافتن بهترین شرایط برای کارفرما ، حقوق بگیران دریافت می کنند. استخدام کنندگان به الزامات فناوری محلی کسب و کار و مکان هایی که موقعیت مهندسی نرم افزار در سطح ابتدایی در دسترس خواهد بود ، اعتقاد دارند.
اگر برای پاسخگویی مشاغل به مشکل برخوردید ، از تماس با یک آژانس نترسید. شما به تنهایی در برخی از شهرها ، حتی به دلیل اعتماد آژانس های استخدام کننده با مشاغل محلی ، کار بدون کمک آژانس کارکنان دشوار است.
با یک آژانس استخدام کار کنید ، روند آنها را درک کنید و چگونه این امر به طور مستقیم بر شغل شما تأثیر می گذارد. همه آژانس ها یا استخدام کنندگان یکسان نیستند و مهم این است که شما و استخدام کننده شما در مورد موقعیت های مورد علاقه خود اهداف یکسانی داشته باشید.
5. بدانید به دنبال چه چیزی هستید.
اگرچه ممکن است دقیقاً ندانید که می خواهید تا آخر عمر چه کار کنید ، اما احتمالاً نوع ساعاتی را که می خواهید در طول هفته کار کنید ، می دانید ، دستمزد مورد انتظار شماو اینکه آیا می خواهید/نیاز به مزایا دارید یا نه.
یکی از بزرگترین چیزهایی که من هنگام ورود به صنعت کشف کردم تفاوت بین کارکنان تمام وقت و پیمانکاران بود. اگرچه خود عناوین ذاتاً تفاوتی در کار موردنظر ندارند ، اما بر میزان دستمزد شما ، تعطیلات ، مزایا و امنیت کلی شغل تأثیر می گذارد. قبل از شروع جستجوی خود و مذاکره درباره حقوق و دستمزد ، مواردی را که باید به آنها توجه کنید بنویسید:
برخی افراد آرزوی داشتن موقعیت تمام وقت با یک سازمان خاص (مزایای کامل ، PTO و تعطیلات تعطیل) را دارند ، اما ممکن است مجبور شوید قبل از اینکه کارفرما مایل به استخدام تمام وقت شما باشد ، به عنوان پیمانکار در آنجا کار کنید. در حین شبکه سازی در بازار منطقه خود تحقیق کنید. ممکن است اکنون از نظر مالی انعطاف پذیر باشید اما در چند سال به ثبات بیشتری احتیاج دارید ، هرگز نمی دانید.
همچنین ... نکته مهم.
هر کجا که فرود می آیید ، احتمال حضور بیشتر شما در آنجا وجود دارد. از 3 سال بسیار کم است در سال 2017 ، صنعت مهندسی نرم افزار بالاترین گردش مالی را در بین سایر صنایع داشت و دلیل خوبی هم داشت. بین تقاضا و افزایش غرامت برای جلب مهندسان با استعداد ، هزینه زمان شما با کار بیشتر به میزان قابل توجهی افزایش می یابد. این را در نظر داشته باشید زیرا منتظر پذیرش اولین موقعیت خود هستید. احتمالاً برای همیشه آنجا نخواهید بود ، بنابراین چه سازش هایی می توانید برای یک یا دو سال انجام دهید؟
6. ارزش شما! = مبلغی که به شما پرداخت می شود
یکی از سخت ترین توصیه هایی که من باید بپذیرم این واقعیت بود که دستمزدی که به من پیشنهاد می شود به طور مستقیم با ارزش من به عنوان یک حرفه ای برابری نمی کند.
به صورت فرضی ، فرض می کنیم که من یک کاندیدای عالی برای یک موقعیت سطح ابتدایی هستم. من سخت کوش ، مشتاق و مایل به یادگیری هستم و ارزش معینی در نیروی کار دارم. اگرچه این تفکر بسیار منطقی است ، لزوماً در مورد مذاکرات حقوق و دستمزد ، کسب و کارها اینطور فکر نمی کنند.
علیرغم اشتیاق خود برای جذب توسعه دهندگان با استعداد ، آنها هنوز در کسب سود هستند. این می تواند به معنای ارائه حقوق کمتر به کسی باشد که مایل به پذیرش آن است.
شاید لازم باشد حقوق بالقوه خود را "در مورد اینکه چقدر برای ایجاد انگیزه برای رفتن به کار در صبح انگیزه می دهم" در مقابل "چقدر آیا من "ارزش" دارم " این تغییر طرز فکر می تواند عزت نفس و سطح استرس شما را در هنگام شروع مذاکرات با حقوق شما نجات دهد.
احتمال اینکه هدف آنها کمتر از آن چیزی باشد که فکر می کنید "ارزش" دارد ، زیاد است. تا زمانی که افرادی مایل به دریافت حقوق کمتر هستند ، برای شما دشوار خواهد بود کسی را پیدا کنید که مایل به پرداخت آن چیزی باشد که شما فکر می کنید ارزشش را دارید.
اگرچه ممکن است در ابتدا این کار ناامید کننده باشد ، تعداد مورد نیاز برای "بیدار شدن از صبح" با گذشت زمان افزایش می یابد. شما برای همیشه در سطح پایین مقیاس حقوق نخواهید بود. هرچه تجربه بیشتری داشته باشید ،قدرت بیشتری در مذاکره درباره حقوق خود خواهید داشت. مطمئن باشید راههای زیادی برای صعود در صنعت فناوری وجود دارد.
7. با چارچوب های آزمایش و آزمایش آشنا شوید
اگرچه به ندرت در مقطع کارشناسی تحت پوشش قرار می گیرد ، اما تست نرم افزار چیزی است که تقریباً در هر کار توسعه ای با آن روبرو خواهید شد.
به عنوان یک مهندس ، کار شما توسعه راه حل های عالی در کنار اطمینان از این که این راه حل ها عملکرد قبلی را خراب نمی کنند. با استفاده از چارچوب های آزمایشی ، توسعه دهندگان می توانند تشخیص دهند که چه زمانی اشکالات در کد جدید تولید شده تولید می شوند. تولید - محصول. اگرچه هرگز نمی توانید تمام اشکالات را به طور واقعی از بین ببرید ، اما می توانید با استفاده از بهترین روش ها ، مسئولیت محصول را بر عهده بگیرید.
آزمایش می تواند به شما کمک کند تا توسعه دهنده بهتری شوید. همانطور که بوریس بیزر ، مهندس نرم افزار و نویسنده آمریکایی یک بار گفت… تفکری که برای ایجاد یک آزمایش مفید باید انجام شود می تواند اشکالات را قبل از کدگذاری کشف و از بین ببرد-در واقع ، تفکر طراحی آزمایشی می تواند اشکالات را در هر مرحله از ایجاد نرم افزار ، از ایده تا مشخصات ، طراحی ، کد نویسی کشف و از بین ببرد. و بقیه. "
8. از منابع تحصیلات تکمیلی مدرسه خود استفاده کنید
این ممکن است بیهوده به نظر برسد ، اما فراموش نکنید که دانشگاه شما منابع باورنکردنی در اختیار آنها دارد. آنها تولید حرفه ای های جوان و با استعداد آماده برای نیروی کار را به خود اختصاص داده اند. شگفت زده نشوید که مشاغل به طور منظم با آنها تماس می گیرند و از نامزدها درخواست می کنند. این فرصتها را فقط در صورتی خواهید یافت که برای صحبت با آنها وقت بگذارید و از آنها بپرسید!
من از یک دانشگاه خصوصی خصوصی فارغ التحصیل شدم و حتی در آنجا منابع قابل توجهی برای کمک به من در تأمین اولین تحصیلاتم وجود داشت. کار. بین داوران رزومه ، مخاطبین شرکت های محلی و حتی آگهی های فرصت شغلی منحصر به فرد ، دانشگاه ها منابع زیادی دارند.
نمایشگاه های شغلی را که دائماً در سطح شهر در حال رخ دادن است ، فراموش نکنیم! وقت بگذارید و منابع موجود را بررسی کنید. ممکن است از کمکی که آنها ارائه می دهند خوشحال شوید.
9. اغلب مصاحبه
اغلب ، ما در حین جستجوی کار فشار زیادی را بر خود وارد می کنیم. اگر شما هم مانند من هستید ، مصاحبه ها اضطراب آور ، اعصاب خردکن و در کل یک تجربه ناخوشایند است. با این حال ، همه اینها صرفاً به دلیل بی تجربگی در عمل واقعی مصاحبه است.
اگر در مورد افرادی که با آنها صحبت می کنید راحت نیستید و نمی دانید دقیقاً به دنبال چه چیزی هستند ، شما عصبی می شوند! بهترین راه مبارزه با اضطراب مصاحبه چیست؟ … مصاحبه های بیشتر.
در طول دوران حرفه ای خود ، در مکان های متعددی کار خواهید کرد ، بنابراین تبدیل شدن به یک "مصاحبه کننده حرفه ای" برای شما مفید خواهد بود. شما قبلاً می دانید که در آن نمی مانیدبرای همیشه در همان مکان ، بنابراین گفتگو درباره سایر فرصتهای شغلی چه ضرری دارد؟ اگر با موقعیت هایی مصاحبه می کنید که لزوماً نمی خواهید آنها را بپذیرید ، مصاحبه برای مشاغلی که بسیار به آنها علاقه دارید بسیار آسان تر خواهد بود.
همیشه مطمئن باشید که گزینه های خود را باز نگه دارید. در مورد پذیرش نکته شماره 10 واقعاً شما را برای موفقیت آماده می کند.
و در آخر…
10. مطمئن شوید که شما و خانواده تان شماره 1 هستید. همیشه.
این واقعاً آغاز یکی از بزرگترین ماجراهای زندگی شما است. شما در زمینه ای بسیار بزرگ هستید که از شغل خود متنفر هستید و این یک چیز شگفت انگیز است. اگر در این سه سال چیزی آموخته باشم ، می گویم هیچ چیز ارزش قربانی کردن روابطم را ندارد. حتی یک شغل با درآمد عالی نیز نیست. آن شغل اول ، بدست آوردن کار بعدی بسیار ساده تر خواهد بود. ایده ترک شغلی که به شما چیزهای زیادی آموخته است می تواند ترسناک باشد اما به یاد داشته باشید که در نهایت سرمایه داری با احساس گرایی خوب بازی نمی کند.
در دنیایی که به سرعت تغییر می کند ، مهم است تا خود و تحصیلات مداوم خود را در اولویت شغل خود قرار دهید. هر چه بهتر بتوانید موقعیت خود را در آن قرار دهید ، بهتر می توانید از خانواده و آینده خود مراقبت کنید. و در پایان روز این مهمترین چیز است.
 خودم خارج از Slalom Consulting LLC (Saint Louis، MO) ، اولین کارفرمای من به عنوان مهندس نرم افزار. من به طور رسمی یک ماه پس از فارغ التحصیلی استخدام شدم و نمی توانستم خوشحال تر باشم.
خودم خارج از Slalom Consulting LLC (Saint Louis، MO) ، اولین کارفرمای من به عنوان مهندس نرم افزار. من به طور رسمی یک ماه پس از فارغ التحصیلی استخدام شدم و نمی توانستم خوشحال تر باشم. امیدوارم این توصیه ها به اندازه من برای شما مورد توجه قرار گیرد. در این صنعت فضای زیادی برای همه ما وجود دارد و هرکسی که با آن ملاقات می کنید تجربیاتی دارد که می توانید از آنها درس بگیرید. اگر توصیه بزرگی دارید که فکر می کنید فارغ التحصیلان جدید باید بدانند ، لطفاً آن را در نظرات زیر به اشتراک بگذارید!
با تشکر از خواندن شما و آرزوی موفقیت برای شما در شغل شغلی شما.
جنا پالمر ،jpalmerproject (توییتر)
آموزش بیشتر 10 کتاب برای تهیه برنامه نویسی فنی/برنامه نویسی مصاحبه های شغلی 10 کتاب الگوریتمی که هر برنامه نویس باید بخواند 5 کتاب ساختار داده و الگوریتم برتر برای توسعه دهندگان جاوا 101 مشکل در کد نویسی و چند نکته مصاحبه برای مبتدیان 20+ مشکلات برنامه نویسی مبتنی بر رشته از مصاحبه ها بیش از 20 مشکل لیست مرتبط از مصاحبه ها بیش از 20 الگوریتم اساسی بر اساس مشکلات ناشی از مصاحبه است 50+ ساختار داده و الگوریتم سوالات مصاحبه 10 دوره برای یادگیری الگوریتم برای شکستن مصاحبه های برنامه نویسی