یافتن خط قوی با استفاده از تکنیک های پیشرفته بینایی رایانه ای: به روزرسانی در اواسط پروژه
یافتن خط قوی با استفاده از تکنیک های پیشرفته بینایی رایانه ای: به روزرسانی در اواسط پروژه
یافتن خط برای توسعه الگوریتم ها برای روبات های خودران یا اتومبیل های خودران بسیار مهم است. الگوریتم یافتن خط باید برای تغییر شرایط نور ، شرایط آب و هوا ، سایر خودروها/وسایل نقلیه در جاده ، انحنای جاده و نوع جاده خود قوی باشد. در این پست ، ما یک الگوریتم مبتنی بر تکنیک های پیشرفته بینایی رایانه برای شناسایی خطوط چپ و راست از فیلم دوربین نصب شده در خط تیره ارائه می دهیم. ما الگوریتم خط یابی را در مراحل زیر پیاده سازی کردیم ،
در ادامه هر مرحله را با جزئیات مرور می کنیم. نتیجه نهایی فرآیند بالا در زیر ارائه شده است ،
ویدئوی زیر یک نمای تشخیصی از تمام مراحل تهیه ویدیوی بالا ارائه می دهد.
مرحله 1: عدم تحریف تصویر دوربین و اعمال آن تبدیل پرسپکتیو.
وقتی لنز دوربین تصویری را ثبت می کند ، تصویر واقعی را ضبط نمی کند ، بلکه اعوجاج تصویر اصلی را ثبت می کند. نقاط مرکز تصویر دارای اعوجاج کمتری هستند در حالی که نقاط دورتر از مرکز دارای اعوجاج بیشتری هستند. این اعوجاج می تواند ناشی از تفاوت در فاصله از مرکز دوربین ، خم شدن دیفرانسیل اشعه در محل مختلف لنز یا اعوجاج چشم انداز باشد. مقاله خوبی در مورد انواع مختلف اعوجاج در اینجا یافت می شود.
بنابراین ، اولین مرحله در پردازش تصویر ، عدم تحریف تصویر اصلی است. شرح خوبی از الگوریتم مورد استفاده برای عدم تحریف تصویر دوربین را می توانید در اینجا پیدا کنید. برای الگوریتم ما ، ابتدا ماتریس اعوجاج دوربین و پارامترهای اعوجاج را با استفاده از تصاویر ارائه شده روی صفحه شطرنج محاسبه کردیم. سپس ماتریس دوربین را بارگذاری کرده و از آن برای عدم تحریف تصاویر استفاده می کنیم. شکل زیر نتیجه عدم تحریف را نشان می دهد. آخرین پانل تفاوت بین تصویر اصلی و تحریف نشده را نشان می دهد.
 حذف اعوجاج تصویر < /img>
حذف اعوجاج تصویر < /img> در مرحله بعد ما از دگرگونی چشم انداز برای به دست آوردن نمای پرنده از جاده استفاده کردیم. ما این کار را با شناسایی 4 نقطه در تصویر اصلی دوربین و سپس کشیدن تصویر به گونه ای انجام دادیم که ناحیه بین 4 نقطه یک قسمت مستطیل شکل ایجاد می کند.
 تغییر چشم انداز برای مشاهده نمای پرنده
تغییر چشم انداز برای مشاهده نمای پرنده هنگامی که نمای بالایی به دست آمد ، به خطوط idenfiy ادامه دادیم.
< مرحله 2: تبدیل به فضای رنگی HSV و استفاده از ماسک های رنگیمرحله بعدی تبدیل تصویر RGB از نمای پرنده به رنگ بندی HSV بود. HSV به رنگ ، اشباع و ارزش اشاره دارد. طرح HSV به عنوان روشی بصری تر برای نشان دادن رنگ توسعه یافت. Hue (یا H) نشان دهنده رنگ خاص ، اشباع (یا S) مقدار رنگ و مقدار (یا V) روشنایی نسبت به روشنایی مشابه استسفید. بنابراین ، با تبدیل تصاویر به مقیاس HSV ، تمایز رنگ خوبی به دست می آید. ما از فضای رنگ HSV برای شناسایی رنگهای زرد و سفید استفاده کردیم. ما ماسک زرد را به عنوان
yellow_hsv_low = np.array ([0 ، 80 ، 200]) استفاده کردیم yellow_hsv_high = np.array ([40 ، 255 ، 255]) res = apply_color_mask (image_HSV ، warped ، yellow_hsv_low ، yellow_hsv_high)
جایی که apply_color_mask پیکسل هایی با شدت مشخص شده بین مقادیر کم و زیاد را برمی گرداند. نتیجه استفاده از ماسک زرد ،
 اعمال ماسک زرد
اعمال ماسک زرد از آنجا که ماسک زرد در شرایط مختلف نور بسیار قوی است ، زیرا با تغییر کانال روشنایی ، در حالی که رنگ یا رنگ را ثابت نگه می دارید ، تصاویر مختلف رنگ زرد ایجاد می شود. شکلهای زیر تأثیر استفاده از ماسک زرد ما را در شرایط مختلف نور نشان می دهد.
 زرد ماسک در قسمت سایه دار و روشن جاده
زرد ماسک در قسمت سایه دار و روشن جاده  ماسک زرد در قسمت روشن جاده < /img>
ماسک زرد در قسمت روشن جاده < /img> به طور مشابه یک ماسک سفید با استفاده از آستانه به عنوان
white_hsv_low = np.array ([20 ، 0 ، 200]) white_hsv_high = np.array ([255 ، 80 ، 255])
برای شناسایی خطوط سفید ،
 استفاده از ماسک سفید ،
استفاده از ماسک سفید ، هنگامی که ماسک های زرد و سفید اعمال شد ، خطوط ماسک رنگی با ترکیب دو ماسک خط به شرح زیر بدست آمد.
 خط ترکیبی ماسک های رنگی
خط ترکیبی ماسک های رنگی مرحله 3: از فیلترهای اصیل استفاده کنید برای بدست آوردن خط/لبه های احتمالی
مرحله بعدی استفاده از فیلترهای Sobel برای بدست آوردن خطوط/لبه های احتمالی بود. ماسک های رنگی بالا برای انتخاب خطوط خط خوب است ، اگر هیچ علامت زرد یا سفید دیگری در جاده وجود ندارد. این همیشه ممکن نیست زیرا جاده ها می توانند نوشته هایی به رنگ سفید یا زرد روی آنها داشته باشند. بنابراین برای جلوگیری از سردرگمی ، ما همچنین از فیلترهای Sobel برای تشخیص لبه استفاده کردیم. فیلترهای Sobel در پردازش تصویر برای به دست آوردن لبه های یک تصویر با انجام حرکت 2 بعدی تصویر اصلی و اپراتور Sobel (یا فیلترها) استفاده می شوند. این عملیات را می توان به صورت
 فیلتر Sobel ، دایره نشان دهنده عملیات پیچش
فیلتر Sobel ، دایره نشان دهنده عملیات پیچش فیلتر Sobel در امتداد جهت x- و y- شیب یا تغییر در شدت تصویر را در جهت x- و y- ایجاد می کند. این شدت ها را می توان با اندازه و جهت آستانه کرد تا تصویری باینری که در لبه ها برابر 1 است به دست آورد. ما فیلترهای Sobel را اعمال کرده و مقدار شیبها را در جهت x- و y- برای کانالهای S و L تصویر HLS تعیین می کنیم. ما کانال HLS را انتخاب کردیم زیرا در آزمایش های قبلی مشخص شد که HLS color colors برای تشخیص لبه ها قوی تر است.
 فیلتر Sobel اعمال شده در کانال L و S تصویر
فیلتر Sobel اعمال شده در کانال L و S تصویر مرحله 4: ترکیب فیلترهای Sobel و ماسک های رنگی
در ادامه ماسک های دودویی فیلترهای Sobel و ماسک های رنگی را ترکیب کردیم برای به دست آوردن یک شاخص قوی تر برای خطوط. انتظار می رود خطوط دارای علامت های سفید یا زرد در زمینه تیره باشند ، بنابراین انتظار می رود شیب های زیادی را نشان دهند. ماسک تصویر و رنگ Sobel ترکیبی برای خط سفید و زرد در زیر نشان داده شده است.
 ماسک های خطی از فیلترهای Sobel و ماسک های رنگی
ماسک های خطی از فیلترهای Sobel و ماسک های رنگی آخرین ترکیب ماسک خط و لبه از ماسک رنگ و فیلترهای Sobel در زیر ارائه شده است. همانطور که مشهود است ، مناطق موجود در تصویر اصلی که در آن خطوط مورد انتظار است با خطوط ضخیم ضخیم برجسته می شوند. ما توانستیم این خطوط برجسته را بدست آوریم زیرا تشخیص لبه را با آن ترکیب کردیمماسک های رنگی.
 ماسک نهایی خط ترکیبی
ماسک نهایی خط ترکیبی مرحله 5: برای حذف هرگونه علامت گذاری یا ویژگی که ممکن است به دلیل دیگر مصنوعات موجود در تصویر باشد ، از پنجره استفاده کنید.
در ماسک ترکیبی نهایی ، بسیاری از ویژگی های لبه را مشاهده کردیم که می تواند به دلیل دیگر مصنوعات ، برجسته باشد. یکی خط افقی به دلیل کاپوت خودرو بود. بنابراین ما مقدار متوسط همه پیکسل ها را در طول جهت x محاسبه کرده و از یک فیلتر میانگین متحرک برای بدست آوردن توزیع یکنواخت شدت در امتداد جهت x استفاده کردیم. سپس ما آستانه 0.05 را برای شناسایی مناطقی که ممکن است دارای خطوط خط باشند ، اعمال کنیم. این مرزهای منطقه با خطوط آبی نشان داده شده است.
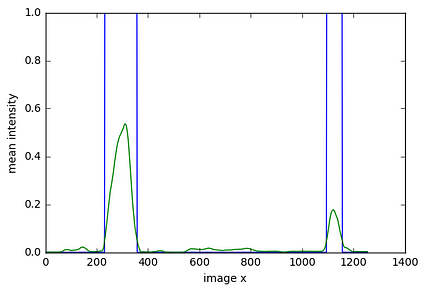 نمودار شدت در جهت X < /img>
نمودار شدت در جهت X < /img> ما از لبه های چپ و راست این قله ها به عنوان محدوده برای انتخاب نقاط برای علامت گذاری خط چپ و راست استفاده کردیم. با حذف نقاط علامت گذاری در خط چپ و راست ، نقاطی را که خطوط را نشان می دهند به عنوان
 علامت گذاری خط چپ و راست
علامت گذاری خط چپ و راست مرحله 6: برای محاسبه خط چپ و راست از رگرسیون چند جمله ای استفاده کنید
سپس از رگرسیون چند جمله ای برای بدست آوردن تناسب درجه دوم برای تقریب خطوط خط استفاده کردیم. ما از تابع برازش چند جمله ای ساده numpy برای محاسبه برازش درجه دو برای خط چپ و راست استفاده کردیم. هنگامی که تناسب درجه دو برای خطوط چپ و راست به دست آمد ، آنها را روی تصویر کشیدیم و منطقه را بین خطوط چپ و راست با رنگ فیروزه ای به صورت زیر علامت گذاری کردیم.
 ترسیم مجدد خطوط خط و بازگشت مجدد روی تصویر اصلی
ترسیم مجدد خطوط خط و بازگشت مجدد روی تصویر اصلی مرحله 7: برای حذف نویز بین ، قاب را برای هموارسازی فریم اعمال کنید تصاویر را بکشید و خطوط را بر روی تصویر ترسیم کنید.
در مرحله بعد ، از طریق فیلتر مرتبه اول ، فریم را برای هموارسازی فریم اعمال کردیم. ما همچنین یک روال رد اختلال را در نظر گرفتیم که هر گونه چند جمله ای را که ضرایب آن از چارچوب قبلی بیش از 5 devi متفاوت بود ، کنار گذاشت.
مرحله 8: محاسبه انحنای خط و انحراف از خط
در نهایت ، ما شعاع انحنا و انحراف از خط را محاسبه کرده و یک سیستم هشدار خروج از خط ساده را اجرا کردیم که در صورت انحراف از خط از 30 سانتی متر ، منطقه فیروزه ای را به قرمز تبدیل می کند.
بازتاب ها
این یک پروژه بسیار جالب و سرگرم کننده بود. جالب ترین بخش این بود که ببینیم چگونه تکنیک های توسعه یافته در یک پروژه ساده قبلی در سناریوی کلی تری به کار گرفته شده است. کار روی این پروژه هنوز به پایان نرسیده است. الگوریتم فعلی آنقدر قوی نیست که بتواند ویدیوها را به چالش بکشد ، اما عملکرد فوق العاده ای دارد. ما در گزارش نهایی خود به جزئیات یک الگوریتم قوی تر می پردازیم.
قدردانی:
از Udacity بسیار سپاسگزارم که مرا برای اولین گروه انتخاب کرد ، این به من امکان اتصال داد با بسیاری از افراد همفکر مثل همیشه ، از بحث با هنریک تانرمن و جان چن چیزهای زیادی آموخت. همچنین از دریافت کمک مالی GPU NVIDA سپاسگزارم. اگرچه ، این برای کار است ، اما من از آن برای Udacity نیز استفاده می کنم.
تشکر ویژه از یکی از دانش آموزان جان چن. جان یک راه حل ساده برای پیاده سازی نمای تشخیصی خط لوله ارسال کرده بود ، اما هنگامی که انجمن از قدیمی تر منتقل شد ، حذف شد. اگرچه ، جان در تعطیلات بود ، اما فوراً کد را بارگذاری کردقطعه ای در انجمن جدید و پیوند را برای من ارسال کرد.

بینایی رایانه ای
بینایی رایانه ای
آیا ترانسفورماتورها جایگزین CNN ها در بینایی رایانه ای می شوند؟
در کمتر از 5 دقیقه ، می دانید که چگونه می توان معماری ترانسفورماتور را با یک مقاله جدید در بینایی رایانه به کار برد. به نام Swin Transformer
 تصویر نویسنده.
تصویر نویسنده. این مقاله به احتمال زیاد نسل بعدی شبکه های عصبی برای همه برنامه های بینایی رایانه است: معماری ترانسفورماتور. مطمئناً قبلاً در مورد این معماری در زمینه پردازش زبان طبیعی یا NLP ، عمدتا با GPT3 که در سال 2020 سر و صدای زیادی ایجاد کرده است ، شنیده اید. ترانسفورماتورها را می توان به عنوان ستون فقرات عمومی برای بسیاری از برنامه های مختلف و نه تنها NLP استفاده کرد. به در عرض چند دقیقه ، می دانید که چگونه می توان معماری ترانسفورماتور را با یک مقاله جدید به نام Swin Transformer توسط Ze Lio و همکاران در بینایی رایانه اعمال کرد. از Microsoft Research [1].
این مقاله ممکن است کمتر از حالت معمول درخشان باشد زیرا نتایج واقعی یک برنامه دقیق را نشان نمی دهد. در عوض ، محققان [1] نشان دادند که چگونه می توان معماری ترانسفورماتورها را از ورودی های متن به تصاویر تطبیق داد و از شبکه های عصبی پیچیده ای از بینایی رایانه پیشی گرفت ، که به نظر من از بهبود کمی جزئی بسیار هیجان انگیز است. و البته ، آنها کد [2] را برای شما ارائه می دهند تا خودتان پیاده سازی کنید! پیوند در منابع زیر است.
چرا از ترانسفورماتورها در شبکه های CNN استفاده کنیم؟
اما چرا ما سعی می کنیم شبکه های عصبی متحرک (CNN) را برای برنامه های بینایی رایانه جایگزین کنیم؟ این به این دلیل است که ترانسفورماتورها می توانند از حافظه بسیار بیشتری استفاده کنند و در مورد کارهای پیچیده بسیار قوی تر هستند. این البته با توجه به این واقعیت است که شما داده هایی برای آموزش آن دارید. ترانسفورماتورها همچنین از مکانیزم توجه معرفی شده در مقاله 2017 استفاده می کنند توجه فقط به آن نیاز دارید [3]. توجه به معماری ترانسفورماتور اجازه می دهد تا به صورت موازی محاسبه شود.
 فرآیند توجه در NLP تصویر توسط Davide Coccomini با اجازه بازنشر می شود. شبکه های CNN بسیار محلی تر هستند و از فیلترهای کوچک برای فشرده سازی اطلاعات به سمت پاسخ کلی استفاده می کنند.
در حالی که این معماری برای کارهای طبقه بندی عمومی قدرتمند است ، اما اطلاعات مکانی لازم برای بسیاری از وظایف مانند تشخیص نمونه را ندارد. این به این دلیل است که پیچیدگی ها روابط پیکسل های فاصله دار را در نظر نمی گیرند.
فرآیند توجه در NLP تصویر توسط Davide Coccomini با اجازه بازنشر می شود. شبکه های CNN بسیار محلی تر هستند و از فیلترهای کوچک برای فشرده سازی اطلاعات به سمت پاسخ کلی استفاده می کنند.
در حالی که این معماری برای کارهای طبقه بندی عمومی قدرتمند است ، اما اطلاعات مکانی لازم برای بسیاری از وظایف مانند تشخیص نمونه را ندارد. این به این دلیل است که پیچیدگی ها روابط پیکسل های فاصله دار را در نظر نمی گیرند. 
 مثال توجه به خود در Transformers برای NLP (چپ) و دید رایانه (راست). تصویر توسط نویسنده. برای معرفی سریع مفهوم توجه ، بیایید یک مثال ساده NLP را ارسال کنیم که یک جمله را برای ترجمه آن به یک شبکه ترانسفورماتور ارسال می کند. در این مورد ، توجه اساساً اندازه گیری نحوه ارتباط هر کلمه در جمله ورودی با هر کلمه در جمله ترجمه خروجی است. به طور مشابه ، چیزی وجود دارد که ما آن را توجه به خود می نامیم و می تواند به عنوان اندازه گیری تأثیر یک کلمه خاص بر همه کلمات دیگر یک جمله تلقی شود. این فرایند مشابه را می توان برای تصاویر محاسبه کننده توجه اعمال کردتکه های تصاویر و روابط آنها با یکدیگر ، همانطور که در مقاله بیشتر بحث خواهیم کرد.
مثال توجه به خود در Transformers برای NLP (چپ) و دید رایانه (راست). تصویر توسط نویسنده. برای معرفی سریع مفهوم توجه ، بیایید یک مثال ساده NLP را ارسال کنیم که یک جمله را برای ترجمه آن به یک شبکه ترانسفورماتور ارسال می کند. در این مورد ، توجه اساساً اندازه گیری نحوه ارتباط هر کلمه در جمله ورودی با هر کلمه در جمله ترجمه خروجی است. به طور مشابه ، چیزی وجود دارد که ما آن را توجه به خود می نامیم و می تواند به عنوان اندازه گیری تأثیر یک کلمه خاص بر همه کلمات دیگر یک جمله تلقی شود. این فرایند مشابه را می توان برای تصاویر محاسبه کننده توجه اعمال کردتکه های تصاویر و روابط آنها با یکدیگر ، همانطور که در مقاله بیشتر بحث خواهیم کرد. 
ترانسفورماتورها در بینایی کامپیوتر
اکنون که می دانیم ترانسفورماتورها بسیار جالب هستند ، هنوز مشکلی در برنامه های بینایی رایانه وجود دارد. در واقع ، درست مانند ضرب المثل رایج "یک تصویر هزار کلمه ارزش دارد" ، تصاویر حاوی اطلاعات بسیار بیشتری نسبت به جملات هستند ، بنابراین ما باید معماری ترانسفورماتور اصلی را برای پردازش م imagesثر تصاویر تطبیق دهیم. این مقاله در مورد این است.
 پیچیدگی ترانسفورماتورهای بینایی. تصویر توسط داوید کوکومینی با مجوز بازنشر می شود. بنابراین زمان محاسبه و نیازهای حافظه افزایش می یابد. در عوض ، محققان این پیچیدگی محاسباتی درجه دوم را با پیچیدگی محاسباتی خطی به اندازه تصویر جایگزین کردند.
پیچیدگی ترانسفورماتورهای بینایی. تصویر توسط داوید کوکومینی با مجوز بازنشر می شود. بنابراین زمان محاسبه و نیازهای حافظه افزایش می یابد. در عوض ، محققان این پیچیدگی محاسباتی درجه دوم را با پیچیدگی محاسباتی خطی به اندازه تصویر جایگزین کردند.  اولین مرحله از معماری Swin Transformer ، نشانه گذاری تصویر. تصویر نویسنده.
اولین مرحله از معماری Swin Transformer ، نشانه گذاری تصویر. تصویر نویسنده. ترانسفورماتور Swin [1] [2]
روند دستیابی به این امر بسیار ساده است. در ابتدا ، مانند اکثر کارهای بینایی رایانه ، یک تصویر RGB به شبکه ارسال می شود. این تصویر به وصله تقسیم می شود و هر پچ به عنوان یک نشانه تلقی می شود. و ویژگی های این توکن ها مقادیر RGB خود پیکسل ها هستند. برای مقایسه با NLP ، می توانید این را به عنوان تصویر کلی جمله ببینید ، و هر پچ کلمات آن جمله است. توجه به خود بر روی هر پچ اعمال می شود ، که در اینجا به آن پنجره می گویند. سپس ، پنجره ها جابجا می شوند و در نتیجه پیکربندی پنجره جدیدی برای اعمال مجدد توجه به خود ایجاد می شود. این امکان ایجاد ارتباط بین پنجره ها را با حفظ بازده محاسبه این معماری پنجره دار فراهم می کند. این امر در مقایسه با شبکه های عصبی پیچشی بسیار جالب است زیرا اجازه می دهد روابط پیکسل های دوربرد ظاهر شود.
 توجه به خود در پنجره ها اعمال می شود. تصویر نویسنده.
توجه به خود در پنجره ها اعمال می شود. تصویر نویسنده. این فقط برای مرحله اول بود. مرحله دوم بسیار مشابه است اما ویژگی های هر گروه دو نفره را با دو تکه مجاور به هم پیوند می دهد و وضوح تصویر را تا دو برابر کاهش می دهد. این روش در مراحل 3 و 4 دو بار تکرار می شود و همان وضوح نقشه ویژگی را ایجاد می کند ، مانند شبکه های معمولی کانولوشن مانند ResNets و VGG. محصولات خوب ، بله و خیر. تصویر نویسنده.
قدرت پیچیدگی در این است که فیلترها از وزن های ثابت در سطح جهانی استفاده می کنند و ویژگی ترجمه-تغییر ناپذیری پیچیدگی را امکان پذیر می کند و آن را به یک تعمیم قدرتمند تبدیل می کند. در توجه به خود ، وزن ها در سطح جهانی ثابت نیستند. در عوض ، آنها بر خود زمینه محلی تکیه می کنند. بنابراین ، توجه به خود هر پیکسل را در نظر می گیرد ، بلکه رابطه آن را با پیکسل های دیگر در نظر می گیرد.
 تغییر پنجره مشکل رابطه طولانی مدت. تصویر توسط نویسنده.
تغییر پنجره مشکل رابطه طولانی مدت. تصویر توسط نویسنده. همچنین ، تکنیک پنجره تغییر یافته آنها امکان نمایش پیکسل های دوربرد را فراهم می کند. متأسفانه ، این روابط طولانی مدت تنها با پنجره های مجاور ظاهر می شود. بنابراین ، از دست دادن روابط بسیار دور ، نشان می دهد که هنوز جایی برای بهبود معماری ترانسفورماتور در مورد بینایی رایانه وجود دارد.
نتیجه گیری
همانطور که در مقاله بیان شده است. :
و من کاملاً موافقم. من فکر می کنم استفاده از معماری مشابه برای بینایی NLP و رایانه می تواند روند تحقیق را به میزان قابل توجهی تسریع کند. البته ، ترانسفورماتورها هنوز به شدت وابسته به داده هستند و هیچ کس نمی تواند بگوید آیا آینده NLP یا دید رایانه ای خواهد بود یا خیر. با این حال ، بدون شک این یک گام مهم برای هر دو زمینه است!
امیدوارم این مقاله بتواند شما را با ترانسفورماتورها و نحوه کاربرد آنها در برنامه های بینایی رایانه آشنا کند.
ممنون که خواندید! مقالات بیشتری مانند این را در وبلاگ من بیابید و آنها را قبل از به اشتراک گذاری در Medium بخوانید!
اگر از کارهای من خوشتان می آید و می خواهید با هوش مصنوعی به روز باشید ، قطعاً باید مرا در وب سایت من دنبال کنید سایر حسابهای رسانه های اجتماعی (LinkedIn ، Twitter) و مشترک خبرنامه هوش مصنوعی هفتگی من شوید!
برای حمایت از من:
مراجع
[1] Liu ، Z. et al.، 2021، "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" ، arXiv preprint https : //arxiv.org/abs/2103.14030v1
[2] Swin Transformer ، Lio ، Z. et al ، کد GitHub ، https://github.com/microsoft/Swin-Transformer
[3] واسوانی ، A. و همکاران ، 2017. "توجه تنها چیزی است که شما نیاز دارید" ، پیش چاپ arXiv https://arxiv.org/a bs/1706.03762.