یافتن خط قوی با استفاده از تکنیک های پیشرفته بینایی رایانه ای: به روزرسانی در اواسط پروژه
یافتن خط قوی با استفاده از تکنیک های پیشرفته بینایی رایانه ای: به روزرسانی در اواسط پروژه
یافتن خط برای توسعه الگوریتم ها برای روبات های خودران یا اتومبیل های خودران بسیار مهم است. الگوریتم یافتن خط باید برای تغییر شرایط نور ، شرایط آب و هوا ، سایر خودروها/وسایل نقلیه در جاده ، انحنای جاده و نوع جاده خود قوی باشد. در این پست ، ما یک الگوریتم مبتنی بر تکنیک های پیشرفته بینایی رایانه برای شناسایی خطوط چپ و راست از فیلم دوربین نصب شده در خط تیره ارائه می دهیم. ما الگوریتم خط یابی را در مراحل زیر پیاده سازی کردیم ،
در ادامه هر مرحله را با جزئیات مرور می کنیم. نتیجه نهایی فرآیند بالا در زیر ارائه شده است ،
ویدئوی زیر یک نمای تشخیصی از تمام مراحل تهیه ویدیوی بالا ارائه می دهد.
مرحله 1: عدم تحریف تصویر دوربین و اعمال آن تبدیل پرسپکتیو.
وقتی لنز دوربین تصویری را ثبت می کند ، تصویر واقعی را ضبط نمی کند ، بلکه اعوجاج تصویر اصلی را ثبت می کند. نقاط مرکز تصویر دارای اعوجاج کمتری هستند در حالی که نقاط دورتر از مرکز دارای اعوجاج بیشتری هستند. این اعوجاج می تواند ناشی از تفاوت در فاصله از مرکز دوربین ، خم شدن دیفرانسیل اشعه در محل مختلف لنز یا اعوجاج چشم انداز باشد. مقاله خوبی در مورد انواع مختلف اعوجاج در اینجا یافت می شود.
بنابراین ، اولین مرحله در پردازش تصویر ، عدم تحریف تصویر اصلی است. شرح خوبی از الگوریتم مورد استفاده برای عدم تحریف تصویر دوربین را می توانید در اینجا پیدا کنید. برای الگوریتم ما ، ابتدا ماتریس اعوجاج دوربین و پارامترهای اعوجاج را با استفاده از تصاویر ارائه شده روی صفحه شطرنج محاسبه کردیم. سپس ماتریس دوربین را بارگذاری کرده و از آن برای عدم تحریف تصاویر استفاده می کنیم. شکل زیر نتیجه عدم تحریف را نشان می دهد. آخرین پانل تفاوت بین تصویر اصلی و تحریف نشده را نشان می دهد.
 حذف اعوجاج تصویر < /img>
حذف اعوجاج تصویر < /img> در مرحله بعد ما از دگرگونی چشم انداز برای به دست آوردن نمای پرنده از جاده استفاده کردیم. ما این کار را با شناسایی 4 نقطه در تصویر اصلی دوربین و سپس کشیدن تصویر به گونه ای انجام دادیم که ناحیه بین 4 نقطه یک قسمت مستطیل شکل ایجاد می کند.
 تغییر چشم انداز برای مشاهده نمای پرنده
تغییر چشم انداز برای مشاهده نمای پرنده هنگامی که نمای بالایی به دست آمد ، به خطوط idenfiy ادامه دادیم.
< مرحله 2: تبدیل به فضای رنگی HSV و استفاده از ماسک های رنگیمرحله بعدی تبدیل تصویر RGB از نمای پرنده به رنگ بندی HSV بود. HSV به رنگ ، اشباع و ارزش اشاره دارد. طرح HSV به عنوان روشی بصری تر برای نشان دادن رنگ توسعه یافت. Hue (یا H) نشان دهنده رنگ خاص ، اشباع (یا S) مقدار رنگ و مقدار (یا V) روشنایی نسبت به روشنایی مشابه استسفید. بنابراین ، با تبدیل تصاویر به مقیاس HSV ، تمایز رنگ خوبی به دست می آید. ما از فضای رنگ HSV برای شناسایی رنگهای زرد و سفید استفاده کردیم. ما ماسک زرد را به عنوان
yellow_hsv_low = np.array ([0 ، 80 ، 200]) استفاده کردیم yellow_hsv_high = np.array ([40 ، 255 ، 255]) res = apply_color_mask (image_HSV ، warped ، yellow_hsv_low ، yellow_hsv_high)
جایی که apply_color_mask پیکسل هایی با شدت مشخص شده بین مقادیر کم و زیاد را برمی گرداند. نتیجه استفاده از ماسک زرد ،
 اعمال ماسک زرد
اعمال ماسک زرد از آنجا که ماسک زرد در شرایط مختلف نور بسیار قوی است ، زیرا با تغییر کانال روشنایی ، در حالی که رنگ یا رنگ را ثابت نگه می دارید ، تصاویر مختلف رنگ زرد ایجاد می شود. شکلهای زیر تأثیر استفاده از ماسک زرد ما را در شرایط مختلف نور نشان می دهد.
 زرد ماسک در قسمت سایه دار و روشن جاده
زرد ماسک در قسمت سایه دار و روشن جاده  ماسک زرد در قسمت روشن جاده < /img>
ماسک زرد در قسمت روشن جاده < /img> به طور مشابه یک ماسک سفید با استفاده از آستانه به عنوان
white_hsv_low = np.array ([20 ، 0 ، 200]) white_hsv_high = np.array ([255 ، 80 ، 255])
برای شناسایی خطوط سفید ،
 استفاده از ماسک سفید ،
استفاده از ماسک سفید ، هنگامی که ماسک های زرد و سفید اعمال شد ، خطوط ماسک رنگی با ترکیب دو ماسک خط به شرح زیر بدست آمد.
 خط ترکیبی ماسک های رنگی
خط ترکیبی ماسک های رنگی مرحله 3: از فیلترهای اصیل استفاده کنید برای بدست آوردن خط/لبه های احتمالی
مرحله بعدی استفاده از فیلترهای Sobel برای بدست آوردن خطوط/لبه های احتمالی بود. ماسک های رنگی بالا برای انتخاب خطوط خط خوب است ، اگر هیچ علامت زرد یا سفید دیگری در جاده وجود ندارد. این همیشه ممکن نیست زیرا جاده ها می توانند نوشته هایی به رنگ سفید یا زرد روی آنها داشته باشند. بنابراین برای جلوگیری از سردرگمی ، ما همچنین از فیلترهای Sobel برای تشخیص لبه استفاده کردیم. فیلترهای Sobel در پردازش تصویر برای به دست آوردن لبه های یک تصویر با انجام حرکت 2 بعدی تصویر اصلی و اپراتور Sobel (یا فیلترها) استفاده می شوند. این عملیات را می توان به صورت
 فیلتر Sobel ، دایره نشان دهنده عملیات پیچش
فیلتر Sobel ، دایره نشان دهنده عملیات پیچش فیلتر Sobel در امتداد جهت x- و y- شیب یا تغییر در شدت تصویر را در جهت x- و y- ایجاد می کند. این شدت ها را می توان با اندازه و جهت آستانه کرد تا تصویری باینری که در لبه ها برابر 1 است به دست آورد. ما فیلترهای Sobel را اعمال کرده و مقدار شیبها را در جهت x- و y- برای کانالهای S و L تصویر HLS تعیین می کنیم. ما کانال HLS را انتخاب کردیم زیرا در آزمایش های قبلی مشخص شد که HLS color colors برای تشخیص لبه ها قوی تر است.
 فیلتر Sobel اعمال شده در کانال L و S تصویر
فیلتر Sobel اعمال شده در کانال L و S تصویر مرحله 4: ترکیب فیلترهای Sobel و ماسک های رنگی
در ادامه ماسک های دودویی فیلترهای Sobel و ماسک های رنگی را ترکیب کردیم برای به دست آوردن یک شاخص قوی تر برای خطوط. انتظار می رود خطوط دارای علامت های سفید یا زرد در زمینه تیره باشند ، بنابراین انتظار می رود شیب های زیادی را نشان دهند. ماسک تصویر و رنگ Sobel ترکیبی برای خط سفید و زرد در زیر نشان داده شده است.
 ماسک های خطی از فیلترهای Sobel و ماسک های رنگی
ماسک های خطی از فیلترهای Sobel و ماسک های رنگی آخرین ترکیب ماسک خط و لبه از ماسک رنگ و فیلترهای Sobel در زیر ارائه شده است. همانطور که مشهود است ، مناطق موجود در تصویر اصلی که در آن خطوط مورد انتظار است با خطوط ضخیم ضخیم برجسته می شوند. ما توانستیم این خطوط برجسته را بدست آوریم زیرا تشخیص لبه را با آن ترکیب کردیمماسک های رنگی.
 ماسک نهایی خط ترکیبی
ماسک نهایی خط ترکیبی مرحله 5: برای حذف هرگونه علامت گذاری یا ویژگی که ممکن است به دلیل دیگر مصنوعات موجود در تصویر باشد ، از پنجره استفاده کنید.
در ماسک ترکیبی نهایی ، بسیاری از ویژگی های لبه را مشاهده کردیم که می تواند به دلیل دیگر مصنوعات ، برجسته باشد. یکی خط افقی به دلیل کاپوت خودرو بود. بنابراین ما مقدار متوسط همه پیکسل ها را در طول جهت x محاسبه کرده و از یک فیلتر میانگین متحرک برای بدست آوردن توزیع یکنواخت شدت در امتداد جهت x استفاده کردیم. سپس ما آستانه 0.05 را برای شناسایی مناطقی که ممکن است دارای خطوط خط باشند ، اعمال کنیم. این مرزهای منطقه با خطوط آبی نشان داده شده است.
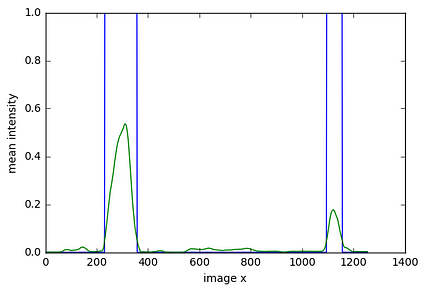 نمودار شدت در جهت X < /img>
نمودار شدت در جهت X < /img> ما از لبه های چپ و راست این قله ها به عنوان محدوده برای انتخاب نقاط برای علامت گذاری خط چپ و راست استفاده کردیم. با حذف نقاط علامت گذاری در خط چپ و راست ، نقاطی را که خطوط را نشان می دهند به عنوان
 علامت گذاری خط چپ و راست
علامت گذاری خط چپ و راست مرحله 6: برای محاسبه خط چپ و راست از رگرسیون چند جمله ای استفاده کنید
سپس از رگرسیون چند جمله ای برای بدست آوردن تناسب درجه دوم برای تقریب خطوط خط استفاده کردیم. ما از تابع برازش چند جمله ای ساده numpy برای محاسبه برازش درجه دو برای خط چپ و راست استفاده کردیم. هنگامی که تناسب درجه دو برای خطوط چپ و راست به دست آمد ، آنها را روی تصویر کشیدیم و منطقه را بین خطوط چپ و راست با رنگ فیروزه ای به صورت زیر علامت گذاری کردیم.
 ترسیم مجدد خطوط خط و بازگشت مجدد روی تصویر اصلی
ترسیم مجدد خطوط خط و بازگشت مجدد روی تصویر اصلی مرحله 7: برای حذف نویز بین ، قاب را برای هموارسازی فریم اعمال کنید تصاویر را بکشید و خطوط را بر روی تصویر ترسیم کنید.
در مرحله بعد ، از طریق فیلتر مرتبه اول ، فریم را برای هموارسازی فریم اعمال کردیم. ما همچنین یک روال رد اختلال را در نظر گرفتیم که هر گونه چند جمله ای را که ضرایب آن از چارچوب قبلی بیش از 5 devi متفاوت بود ، کنار گذاشت.
مرحله 8: محاسبه انحنای خط و انحراف از خط
در نهایت ، ما شعاع انحنا و انحراف از خط را محاسبه کرده و یک سیستم هشدار خروج از خط ساده را اجرا کردیم که در صورت انحراف از خط از 30 سانتی متر ، منطقه فیروزه ای را به قرمز تبدیل می کند.
بازتاب ها
این یک پروژه بسیار جالب و سرگرم کننده بود. جالب ترین بخش این بود که ببینیم چگونه تکنیک های توسعه یافته در یک پروژه ساده قبلی در سناریوی کلی تری به کار گرفته شده است. کار روی این پروژه هنوز به پایان نرسیده است. الگوریتم فعلی آنقدر قوی نیست که بتواند ویدیوها را به چالش بکشد ، اما عملکرد فوق العاده ای دارد. ما در گزارش نهایی خود به جزئیات یک الگوریتم قوی تر می پردازیم.
قدردانی:
از Udacity بسیار سپاسگزارم که مرا برای اولین گروه انتخاب کرد ، این به من امکان اتصال داد با بسیاری از افراد همفکر مثل همیشه ، از بحث با هنریک تانرمن و جان چن چیزهای زیادی آموخت. همچنین از دریافت کمک مالی GPU NVIDA سپاسگزارم. اگرچه ، این برای کار است ، اما من از آن برای Udacity نیز استفاده می کنم.
تشکر ویژه از یکی از دانش آموزان جان چن. جان یک راه حل ساده برای پیاده سازی نمای تشخیصی خط لوله ارسال کرده بود ، اما هنگامی که انجمن از قدیمی تر منتقل شد ، حذف شد. اگرچه ، جان در تعطیلات بود ، اما فوراً کد را بارگذاری کردقطعه ای در انجمن جدید و پیوند را برای من ارسال کرد.

وضعیت بینایی رایانه ای - CVPR 2021
وضعیت بینایی رایانه ای - CVPR 2021
توسط آذین عسگریان و رهیت صحا
Computer Vision (CV) منطقه ای از هوش مصنوعی است که بر توانمندسازی رایانه ها برای شناسایی و پردازش اشیا تمرکز دارد. در تصاویر و فیلم ها به همان روشی که انسان ها انجام می دهند. تا همین اواخر ، بینایی رایانه فقط در ظرفیت محدود کار می کرد. اما به لطف پیشرفت در یادگیری عمیق ، این رشته در سال های اخیر توانسته است جهش های بزرگی داشته باشد و اکنون صنایع مختلف را به سرعت متحول می کند!
 اعتبار:/U/DEADBUILTIN Consolia-comic.com
اعتبار:/U/DEADBUILTIN Consolia-comic.com CV به سرعت در حال حرکت است به طوری که ما عملا در یک سال گذشته تنها یک دهه تغییر داشته ایم ، با بیش از 45000 مقاله در حال چاپ و بسیاری از مدل های هیولا توسط شرکت های بزرگ فناوری مانند OpenAI (به عنوان مثال iGPT [18] و CLIP [10]) و Google (به عنوان مثال ViT-G/14 [19]) منتشر می شوند! پیگیری این زمینه برای همه یک چالش است!
در این پست ، می توانید خلاصه کنفرانس CVPR ما را بخوانید. CVPR (بینایی رایانه و تشخیص الگو) یکی از همایش های پیشرو در زمینه بینایی رایانه است. امسال ، CVPR 83 کارگاه آموزشی ، 30 آموزش ، 50+ حامی و بیش از 1600 مقاله در 12 جلسه (از 7093 مقاله با نرخ پذیرش 23 ~)) داشت.
گرایش های اخیر
در CVPR 2021 ، زمینه های فرعی مختلف CV پیشرفت های امیدوار کننده ای را نشان داده اند. در حالی که برخی از موضوعات ، از جمله تقسیم بندی و طبقه بندی اشیاء ، در چند سال گذشته در مرکز توجه قرار گرفته اند ، موضوعات جدیدی به تازگی پدیدار شده و در سال 2021 به مرکزیت رسیده است. خلاصه ما بر این موضوعات متمرکز است:
ما همچنین مطالب خود را به اشتراک می گذاریم بینش در مورد دو صنعتی که CV در آنها مهم است:
یادگیری با مثالهای خصمانه مرور کلی
یادگیری عمیق و بینایی رایانه ای سیستم ها در کارهای مختلف موفق بوده اند اما نواقص خود را دارند. یکی از مواردی که اخیراً توجه جامعه تحقیقاتی را به خود جلب کرده است ، حساسیت این سیستم ها به نمونه های مخالف است. یک مثال خصمانه ، یک تصویر پر سر و صدا است که برای فریب سیستم به پیش بینی اشتباه طراحی شده است [1]. برای استقرار این سیستم ها در دنیای واقعی ، ضروری است که آنها بتوانند این نمونه ها را تشخیص دهند. برای این منظور ، آثار اخیر با استفاده از مثالهای خصمانه در فرایند آموزش ، امکان تقویت این سیستمها در برابر حملات خصمانه را بررسی می کنند.
مزایا و معایب یادگیری با مثالهای خصمانه
: روشهای متداول یادگیری عمیق ، هر نمونه آموزشی را در مجموعه داده به طور مساوی ، صرف نظر از درستی برچسب ، وزن می کند. این می تواند روند یادگیری را از مسیر خارج کند ، به خصوص اگر برچسب ها حاوی نویز باشند. از طریق یادگیری متقابل ، قابلیت اطمینان هر نمونه را می توان بر اساس پایداری برچسب پیش بینی شده آن هنگام افزودن سطوح مختلف نویز برآورد کرد. این مدل را قادر می سازد تا نمونه هایی را که در برابر سر و صدا مقاوم تر هستند ، شناسایی کرده و بر آنها تمرکز کند و در نتیجه حساسیت آن را به نمونه های مخالف کاهش دهد. علاوه بر این ، نشان داده شده است که نمونه های متخاصم در رژیم های آموزشی از معیارهای وظایف استاندارد مانند طبقه بندی و تشخیص اشیا پیشی گرفته است. این در تنظیمات نیمه تحت نظارت مفید است ، به عنوان مثال ، هنگامی که تعداد محدودی اطلاعات برچسب گذاری شده وجود داشته باشد.
معایب: آموزش متقابل شامل تنظیم پارامتر "epsilon" است که میزان نویز را کنترل می کندبه هر نمونه اضافه می شود "epsilon" که بیش از حد بالا است ممکن است مانع روند یادگیری شود. علاوه بر این ، آزمایشات انجام شده در [2] نشان می دهد که با در دسترس بودن مجموعه داده های بزرگ دارای برچسب ، عملکرد تکنیک های یادگیری تحت نظارت با تکنیک های آموزش خصمانه مطابقت دارد و مزایای آموزش خصومت را کمتر عمیق می کند.
حالت- هنر یادگیری با مثالهای متخاصم
SENTRY: این روش از مثالهای مخالف در زمینه آموزش یادگیری استفاده می کند. یادگیری انتقالی زمینه ای برای یادگیری ماشین است که در آن یک مدل آموزش داده شده بر روی توزیع منبع ، به طور دقیق تنظیم شده و بر اساس توزیع هدف متفاوت ارزیابی می شود. در میان توزیع هدف ، SENTRY به مساوی وزن برابر اختصاص داده شده برای همه نمونه ها می پردازد. با استفاده از روش "سازگاری پیش بینی" ، موارد هدف قابل اعتماد را شناسایی می کند. در این روش ، اطمینان پیش بینی مدل در موارد هدف بسیار سازگار که قابل اعتماد تلقی می شوند ، افزایش می یابد. به طور خاص ، یک نمونه ، همراه با چندین نسخه تقویت شده خود ، به مجموعه ای از مدل ها داده می شود. پیش بینی های هر مدل از نظر ثبات ارزیابی می شود. اگر مدلهای بیشتری در پیش بینی های خود سازگار باشند ، نمونه مورد نظر قابل اعتماد است ، بنابراین باید از آن برای به حداقل رساندن اتروپی استفاده کرد. اگر پیش بینی ها ناسازگار باشند ، نمونه مورد نظر قابل اعتماد نیست و بنابراین ، باید نادیده گرفته شود. با پیروی از این روش ، SENTRY به SOTA در DomainNet [3] دست می یابد که یک مجموعه داده استاندارد برای ارزیابی مدلها در مورد قابلیتهای یادگیری انتقال آنها است.
 مروری بر مدل SENTRY.
مروری بر مدل SENTRY. AdvProp: نشان دادن نمونه های خصمانه در آموزش نشان داده است که عملکرد مدل را بهبود می بخشد و منجر به ویژگی هایی می شود که بیشتر با تفسیر انسانی هم خوانی دارد [4]. این کار مدلهای آموزشی مشترک را بر روی تصاویر تمیز و مخالف بررسی می کند. کارهای قبلی مدل های پیش آموزش را در مورد نمونه های مخالف و سپس تنظیم دقیق روی تصاویر تمیز را بررسی می کند. در حالی که این امر عملکرد طبقه بندی را بهبود می بخشد ، مدل مستعد "فراموشی فاجعه بار" می شود ، جایی که یک مدل ویژگی هایی را که در مرحله قبل از آموزش آموخته است (در مورد تغییر دامنه) فراموش می کند. برای رسیدگی به این مسئله ، لایه های نرمال سازی دسته ای کمکی (BN) برای عادی سازی نمونه های مخالف پیشنهاد شده است. از طرف دیگر ، از لایه های معمولی BN برای عادی سازی تصاویر تمیز استفاده می شود. این به لایه های عادی اجازه می دهد تا بر اساس توزیع های مختلف نمونه های تمیز و مخالف رفتار متفاوتی داشته باشند. در طول استنتاج ، لایه های کمکی BN ریخته می شوند و لایه های معمولی BN برای پیش بینی استفاده می شود. این رژیم آموزشی همراه با EfficientNet به عنوان معماری ستون فقرات ، به عملکرد برتر SOTA 1 در دقت طبقه بندی ImageNet دست می یابد. علاوه بر این ، AdvProp به عملکرد SOTA در نسخه های دشوارتر ImageNet: ImageNet-a ، ImageNet-c و Stylized ImageNet دست می یابد. علاوه بر این ، شامل مثالهای مخالف در آموزش نیز SOTA را در تشخیص شی [5] به دست می آورد.
 مقایسه بین BN سنتی در مقابل BN کمکی.
مقایسه بین BN سنتی در مقابل BN کمکی. یادگیری خودآزمایی و متضاد یادگیری
یادگیری عمیق به داده های دارای برچسب تمیز نیاز دارد که بدست آوردن آنها برای بسیاری از برنامه ها دشوار است. حاشیه نویسی حجم زیادی از داده ها مستلزم نیروی انسانی شدید است که زمان بر و گران است. علاوه بر این ، توزیع داده ها همیشه در دنیای واقعی تغییر می کند و این بدان معناست که مدلها باید دائماً در مورد داده های در حال تغییر آموزش ببینند. روشهای خود نظارتی با استفاده از منابع فراوان داده های بدون برچسب خام برای آموزش مدلها ، برخی از این چالشها را برطرف می کند. که دردر این سناریو ، نظارت توسط خود داده ها (نه حاشیه نویسی های انسانی) ارائه می شود و هدف انجام یک کار بهانه است. وظایف بهانه اغلب اکتشافی هستند (به عنوان مثال ، پیش بینی چرخش) که در آن هر دو ورودی و خروجی از داده های بدون برچسب گرفته می شوند. هدف از تعریف یک وظیفه بهانه این است که مدل ها بتوانند ویژگی های مربوطه را یاد بگیرند که بعداً می توانند برای کارهای پایین دست استفاده شوند (که معمولاً حاشیه نویسی در دسترس هستند). یادگیری خود سرپرستی در سال 2020 هنگامی محبوبیت بیشتری پیدا کرد که سرانجام با عملکرد روشهای کاملاً تحت نظارت شروع به کار کرد. یکی از تکنیک های خاص یادگیری متضاد (CL) است.
CL از یک ایده قدیمی [6] الهام گرفته شده است که موارد مشابه باید در فضای تعبیه شده نزدیک بمانند ، در حالی که موارد غیرمتعارف باید با هم فاصله داشته باشند. برای پیاده سازی این ، CL جفت نمونه تشکیل می دهد. برای یک نمونه معین ، یک جفت مثبت با استفاده از مورد نمونه برداری شده و یک نسخه تقویت شده از آن ایجاد می شود. به طور مشابه ، یک جفت منفی با استفاده از یک مورد و یک مورد متفاوت ایجاد می شود. سپس ، ویژگی ها به گونه ای آموخته می شوند که جفت های مثبت در فضای تعبیه شده نزدیک هستند در حالی که جفت های منفی با هم فاصله زیادی دارند. این اجازه می دهد تا اقلام مشابه در فضای تعبیه شده در کنار هم قرار گیرند. مراکز خوشه ای می توانند معنای معنایی یا کلاس شی را نشان دهند. از آنجا که از برچسب ها استفاده نمی شود ، CL می تواند از فراوانی داده های بدون برچسب خام استفاده کند.
مزایا و معایب یادگیری خود سرپرستی و متقابل
مزایا: یادگیری خود سرپرستی یک داده است الگوی یادگیری کارآمد روشهای یادگیری تحت نظارت به مدلها می آموزد که در یک کار خاص خوب عمل کنند. از سوی دیگر ، یادگیری خود سرپرستی به شما امکان می دهد تا موارد کلی را بیاموزید که برای حل یک کار خاص تخصصی ندارند ، بلکه آمارهای غنی تری را برای انواع کارهای پایین دستی در بر می گیرد. از بین همه روشهای تحت نظارت خود ، استفاده از CL کیفیت ویژگی های استخراج شده را بیشتر می کند. ماهیت داده کارآمد یادگیری تحت نظارت ، آن را برای برنامه های کاربردی آموزش یادگیری مطلوب می کند.
معایب: بسیاری از موفقیت های یادگیری تحت نظارت خود را می توان به بزرگنمایی های تصویری با دقت انتخاب شده مانند بزرگنمایی ، محو شدن و برش نسبت داد. به بنابراین ، انتخاب مجموعه مناسب و میزان تقویت برای یک کار خاص می تواند یک فرآیند چالش برانگیز باشد. علاوه بر این ، CL ممکن است مدل را گمراه کند تا بین دو تصویر حاوی یک شیء یکسان تمایز قائل شود. به عنوان مثال ، برای تصویری از اسب ، برای ایجاد جفت منفی ، CL ممکن است تصویر دیگری را انتخاب کند که شامل اسب است. در این مورد ، آنچه مدل به عنوان یک جفت منفی در نظر می گیرد ، در واقع یک جفت مثبت است. یادگیری ساده نمایندگی سیامی: چارچوب شبکه سیامی معماری است که در یادگیری خود سرپرستی محبوبیت یافته است. بر خلاف CL که جفت های مثبت و منفی ایجاد می کند ، این چارچوب فقط شباهت بین بزرگنمایی یک تصویر را به حداکثر می رساند ، که به یادگیری نمایش های مفید کمک می کند. کارهای موازی در یادگیری خود سرپرستی از تلفات متضاد استفاده می کنند و موفقیت این آثار متکی به (i) استفاده از جفت های منفی [7] ، (ii) اندازه دسته ، و (iii) رمزگذارهای حرکت [8] است. SimSiam ، با این حال ، به این عوامل تکیه نمی کند ، و در انتخاب آنها قوی تر می شودهایپر پارامترها علاوه بر این ، SimSiam از تکنیک "stop-gradient" برای جلوگیری از سقوط ویژگی استفاده می کند. فروپاشی ویژگی پدیده ای است که در آن یک مدل میانبر را برای به حداقل رساندن عملکرد هدف بدون یادگیری نمایش های مفید یاد می گیرد. در نتیجه ، ویژگی های آموخته شده قابل تعمیم نیستند. با اجتناب از فروپاشی ویژگی ، SimSiam به نتایج رقابتی در ImageNet و کارهای بعدی آن مانند تشخیص شیء COCO و تقسیم بندی نمونه می رسد.
 معماری سیم سیم. معماری ستون فقرات مورد استفاده ، ترانسفورماتور است [10] ، که نشان داده شده است که برتر از شبکه های کانولوشن است. [اگر علاقمند به کسب اطلاعات بیشتر در مورد DINO هستید ، این ویدیو را ببینید]. با استفاده از ترانسفورماتور + چارچوب DINO ، SOTA برای کارهای طبقه بندی تصویر بهبود یافته است. DINO را می توان در برنامه هایی مانند تشخیص کپی و بازیابی تصویر اعمال کرد. با توجه به تصویر پرس و جو ، همه نسخه های ممکن از آن تصویر در اسرع وقت بازیابی می شود. علاوه بر این ، DINO قابلیت تقسیم بندی را به صورت رایگان ارائه می دهد. مشخص شده است که ویژگیهای آموخته شده در DINO در مقایسه با روشهای تحت نظارت در ایجاد نقشه برجسته بهتر است. سرانجام ، با آستانه گذاری دقیق ، DINO می تواند خارج از جعبه برای تقسیم بندی شیء ویدیویی در هر فریم بدون آموزش ثبات زمانی استفاده شود.
معماری سیم سیم. معماری ستون فقرات مورد استفاده ، ترانسفورماتور است [10] ، که نشان داده شده است که برتر از شبکه های کانولوشن است. [اگر علاقمند به کسب اطلاعات بیشتر در مورد DINO هستید ، این ویدیو را ببینید]. با استفاده از ترانسفورماتور + چارچوب DINO ، SOTA برای کارهای طبقه بندی تصویر بهبود یافته است. DINO را می توان در برنامه هایی مانند تشخیص کپی و بازیابی تصویر اعمال کرد. با توجه به تصویر پرس و جو ، همه نسخه های ممکن از آن تصویر در اسرع وقت بازیابی می شود. علاوه بر این ، DINO قابلیت تقسیم بندی را به صورت رایگان ارائه می دهد. مشخص شده است که ویژگیهای آموخته شده در DINO در مقایسه با روشهای تحت نظارت در ایجاد نقشه برجسته بهتر است. سرانجام ، با آستانه گذاری دقیق ، DINO می تواند خارج از جعبه برای تقسیم بندی شیء ویدیویی در هر فریم بدون آموزش ثبات زمانی استفاده شود.  نتایج بخش بندی از روشهای تحت نظارت در مقابل DINO.
نتایج بخش بندی از روشهای تحت نظارت در مقابل DINO. مروری بر مدلهای زبان بینایی
Vision-Language (VL) شامل سیستمهای آموزشی است که درک مشترکی از روشهای تصویر و متن دارند. VL شبیه نحوه تعامل انسانها با جهان است. بینایی بخش بزرگی از نحوه درک انسانها از جهان است و زبان بخش بزرگی از نحوه ارتباط انسانها است. مدلهای VL یک فضای تعبیه مشترک با روشهای مختلف داده را یاد می گیرند. برای آموزش ، از جفت های تصویر و متن استفاده می شود ، جایی که متن معمولاً تصویر را توصیف می کند. بیشتر کارهای اخیر در این زمینه از آموزش مبتنی بر ترانسفورماتور برای نظارت بر خود برای استخراج ویژگی ها از داده ها استفاده می کند. در یک نکته مماس ، از جفت های ویدئویی-متنی برای یادگیری تصاویر غنی و متراکم استفاده شده است. با این حال ، هنوز یک زمینه نوپا با پتانسیل بالا است. به علاوه بر این ، تعداد زیادی از داده ها ، مانند فیلم های YouTube و حاشیه نویسی های خودکار ، می توانند برای آموزش این سیستم ها استفاده شوند. مشابه یادگیری تحت نظارت خود ، ویژگی های آموخته شده جهانی هستند و می توانند برای چندین وظیفه پایین دست مانند
علاوه بر این ، مدلهای VL را می توان برای یادگیری ویژگیهای بصری بهتر و برای تقویت نمایش زبان به عنوان
پیشرفته ترین مدلهای زبان دید
< p> VinVL: بازبینی نمایندگی های بصری در مدل های زبان دید: VinVL بر روی نمایش های بصری برای کارهای VL بهبود می یابد. مدلهای VL به طور کلی دارای یک مدل آشکارساز شی هستندو مدل استخراج زبان به دنبال یک مدل تلفیقی. مدل تلفیقی مسئول ادغام تعبیه های بصری و زبانی است. مدلهای قبلی VL عمدتا بر بهبود مدل همجوشی بینایی-زبان [15] متمرکز بوده اند در حالی که مدل تشخیص شیء را دست نخورده نگه داشته است. VinVL نشان می دهد که ویژگی های بصری در مدل های VL بسیار مهم هستند و یک مدل تشخیص شی بهبود یافته را پیشنهاد می کند. مدل تشخیص شیء ، جعبه های محدود کننده ای را تشخیص می دهد که تقریباً تمام مناطق معنایی تصویر را پوشش می دهند ، در مقابل جعبه های مرزی سنتی که فقط اشیاء مهم را پوشش می دهند. سرانجام ، ویژگی های بصری با جاسازی زبان از طریق ترانسفورماتور ادغام می شوند [16]. پس از پیش آموزش روی مجموعه داده های متعدد ، VinVL برای چندین وظیفه پایین دستی (VQA ، IC و غیره) مجدداً راه اندازی می شود و عملکرد SOTA را در هفت معیار عمومی به دست می آورد. مزایای عملکرد را می توان به بهبود مدل تشخیص شی نسبت داد. مقایسه جعبه های پیش بینی با استفاده از مدل استاندارد تشخیص شیء (چپ) در مقابل مدل تشخیص بهبود یافته VinVL (راست). و اندازه داده های آموزش با این حال ، در سناریوهای دنیای واقعی ، حجم زیادی از داده های دارای برچسب معمولاً گران هستند یا به آسانی در دسترس نیستند. این موضوع با در نظر گرفتن کلاسهای بصری که نیاز به حاشیه نویسی بر اساس دانش متخصص دارند (به عنوان مثال ، تصویربرداری پزشکی) ، کلاسهایی که به ندرت اتفاق می افتد ، یا کارهایی که برچسب زدن به تلاش زیادی نیاز دارد (به عنوان مثال ، تقسیم بندی تصویر) ، حتی این مسئله نیز شدیدتر می شود. در دهه گذشته ، زمینه های مختلف تحقیقاتی برای حل این چالش ها پدید آمده است. زمینه هایی مانند یادگیری تحت نظارت ضعیف ، یادگیری انتقال یافته و خود/نیمه تحت نظارت سعی در غلبه بر این چالش ها با امکان مدل های ML برای یادگیری از نظارت محدود ، ضعیف یا پر سر و صدا دارند. از آنجا که خود/نیمه تحت نظارت در بالا توضیح داده شده است ، در اینجا ما عمدتا بر یادگیری با نظارت ضعیف و انتقال یادگیری تمرکز می کنیم.
مقایسه جعبه های پیش بینی با استفاده از مدل استاندارد تشخیص شیء (چپ) در مقابل مدل تشخیص بهبود یافته VinVL (راست). و اندازه داده های آموزش با این حال ، در سناریوهای دنیای واقعی ، حجم زیادی از داده های دارای برچسب معمولاً گران هستند یا به آسانی در دسترس نیستند. این موضوع با در نظر گرفتن کلاسهای بصری که نیاز به حاشیه نویسی بر اساس دانش متخصص دارند (به عنوان مثال ، تصویربرداری پزشکی) ، کلاسهایی که به ندرت اتفاق می افتد ، یا کارهایی که برچسب زدن به تلاش زیادی نیاز دارد (به عنوان مثال ، تقسیم بندی تصویر) ، حتی این مسئله نیز شدیدتر می شود. در دهه گذشته ، زمینه های مختلف تحقیقاتی برای حل این چالش ها پدید آمده است. زمینه هایی مانند یادگیری تحت نظارت ضعیف ، یادگیری انتقال یافته و خود/نیمه تحت نظارت سعی در غلبه بر این چالش ها با امکان مدل های ML برای یادگیری از نظارت محدود ، ضعیف یا پر سر و صدا دارند. از آنجا که خود/نیمه تحت نظارت در بالا توضیح داده شده است ، در اینجا ما عمدتا بر یادگیری با نظارت ضعیف و انتقال یادگیری تمرکز می کنیم. مزایا و معایب یادگیری با داده های محدود
مزایا: یادگیری با نظارت ضعیف و انتقال یادگیری به کاهش میزان داده های برچسب گذاری شده برای آموزش مدل های CV و در نتیجه افزایش کاربرد و پذیرش این مدل ها در صنعت کمک می کند. یادگیری با نظارت ضعیف همچنین می تواند به مدل ها کمک کند تا در حضور برچسب های پر سر و صدا عملکرد بهتری داشته باشند ، که اغلب در محیط های واقعی مشاهده می شود. علاوه بر این ، روشهای یادگیری انتقال مبتنی بر نمونه را می توان برای غلبه بر چالش های عدم تعادل کلاس (به عنوان مثال ، توزیع طولانی مدت جهان بصری [17]) که به طور طبیعی با مجموعه داده های دنیای واقعی به وجود می آید ، استفاده کرد.
معایب: یادگیری با نظارت ضعیف و یادگیری انتقال هر دو زمینه های نسبتاً جدیدی هستند و هنوز قبل از استفاده در صنعت به زمان نیاز دارند. این روشها اغلب بر اساس معیارهای جمع آوری شده از محیط های کنترل شده توسعه و ارزیابی می شوند و بنابراین عملکرد آنها معمولاً وقتی در محیط های واقعی آزمایش می شوند کاهش می یابد. علاوه بر این ، بیشتر مقالات جالب در این زمینه ها بر اساس مفروضاتی است که در محیط های تحقیق وجود دارد ، اما نه لزوماً در محیط های واقعی. مراقب مفروضات ضمنی و صریح در این مقاله ها هنگام استفاده از آنها برای حل مشکلات دنیای واقعی باشید.
پیشرفته ترین روش یادگیری با داده های محدود
WyPR: تشخیص نقطه با نظارت ضعیف: WyPR یک ابر نقطه ای را به عنوان ورودی می گیرد و به طور مشترک به تقسیم بندی ، تولید پیشنهاد و تشخیص می پردازد. پرداختن مشترک به این وظایف چندین مزیت دارد از جمله:
WyPR با استفاده از روشهای چند مرحله ای (MIL) و تکنیک های خودآموزی با ضررهای سازگاری اضافی که در وظایف و تحولات تعریف شده است ، آموزش می بیند. WyPR نسبت به روش های تقسیم بندی قبلی 6.3٪ mIoU در داده های ScanNet عملکرد بهتری دارد. به طور مشابه ، از روش های پیشنهادی قبلی برای ایجاد و تشخیص پیشنهاد در ScanNet پیشی می گیرد.
 مروری بر چارچوب WyPR.
مروری بر چارچوب WyPR. DatasetGAN: DatasetGAN برای ایجاد داده های آموزشی واقع گرایانه-اعم از تصاویر و برچسب ها ، از شبکه های مخالف تولیدی (GANs) و یادگیری چند مرحله ای (زیر زمینه یادگیری انتقال) استفاده می کند. این روش بر اساس StyleGAN [20] ساخته شده است که جدیدترین مدل برای تولید تصاویر واقعی است. StyleGAN به طور پیش فرض فقط تصاویر ایجاد می کند. برای فعال کردن StyleGAN برای ایجاد برچسب (به عنوان مثال ، نقشه های تقسیم بندی معنایی) علاوه بر تصاویر ، آنها یک شاخه برچسب به بلوک سنتز در StyleGAN اضافه می کنند. شاخه برچسب تنها چند لایه پرسپترون چند لایه است که در این کار با 16 نمونه برچسب آموزش داده شده است. این مقاله نشان می دهد که این روش حتی با یک نمونه برچسب دار می تواند نتایج معقولی را به دست آورد و در صورت ارائه 30 نمونه برچسب دار ، عملکرد روشهای کاملاً تحت نظارت را بدست می آورد. علاوه بر این ، نویسندگان نشان می دهند که می توان از همان ایده برای تولید فیلم های مصنوعی با برچسب [21] استفاده کرد.
 تصویرسازی مراحل مختلف در DatasetGAN.
تصویرسازی مراحل مختلف در DatasetGAN. جلسات جالب-خرده فروشی
از بررسی خودکار تا توصیه محصول ، CV به شرکت های خرده فروشی کمک کرده است تا در گذشته گام های مهمی بردارند. چند سال. در زیر چند نمونه از شرکت ها و استارتاپ هایی که از CV برای افزایش تجربه خرده فروشی خود استفاده می کنند آورده شده است:
جلسات جالب-رانندگی مستقل
وسایل نقلیه خودران در مرکز توجه قرار گرفته اند چند سال. در چندین شرکت و استارتاپ سرمایه گذاری شده استخودروهای خودران مانند گوگل ، تسلا ، اوبر ، تویوتا و واآبی به چند مورد اشاره می کنند. در حالی که اصول اساسی دستیابی به سطح 5 خودمختاری ، یعنی زمانی که خودرو بدون دخالت انسان حرکت می کند ، ثابت است ، رهبران این فضا نظرات متفاوتی در مورد عملکرد بهتر سنسورها دارند. خودروهای خودران از سنسورهای گسترده ای برای بدست آوردن اطلاعات در مورد محیط اطراف خود استفاده می کنند. این داده ها سپس به مدل های CV داده می شوند تا پیش بینی هایی را که برای رانندگی مستقل لازم است بدست آورند. برخی از شرکتها سنسورهای دوربین را به عنوان استاندارد طلا در نظر گرفته اند در حالی که برخی دیگر ترجیح می دهند ترکیبی از سنسورهای دوربین و رادار باشد. پیش بینی کنید این تیم به طور تجربی مزایای استفاده از سنسورهای دوربین را نسبت به رادار نشان داد. ایلان ماسک ، مدیرعامل تسلا حتی در این مورد توییت کرد! علاوه بر این ، تیم استدلال می کند که سنسورهای دوربین ارزان تر از رادار هستند و از نظر تولید در مقیاس مقرون به صرفه تر هستند. در مقایسه با رقبای خود ، تسلا در حال حاضر هزاران اتومبیل خودران در خیابان دارد. این به آنها امکان می دهد داده های زمان واقعی شرایط رانندگی منحصر به فرد را که در طول آموزش لحاظ نشده اند ، جمع آوری کنند. به همین منظور ، تسلا دارای زیرساختی به نام "ناوگان" است و تنها هدف آن جمع آوری داده ها در مورد شرایط مختلف رانندگی از نقاط مختلف جهان است. تسلا با ایدئولوژی "داده های بزرگ = خلبان خودکار حل شده است" ، پیشگام تحقیقات و توسعه در صنعت رانندگی خودران است. مقالات جالب
حفظ پرواز در صورت خرابی موتور کوادکوپتر
حفظ پرواز در صورت خرابی موتور کوادکوپتر
اگر در هواپیما پرواز می کنید و یکی از موتورهای جت ناگهان خراب می شود ، هواپیما فقط از آسمان سقوط نمی کند. خلبان می تواند از موتورهای باقیمانده و قابلیت سر خوردن ذاتی هواپیما برای انجام فرود اضطراری کنترل شده استفاده کند. در صورت خرابی موتور ، حتی خلبانان هلیکوپتر می توانند از تکنیکی به نام autorotation استفاده کنند تا به آرامی پایین بیایند. اما ، ما همچنان انتظار داریم هواپیماهای بدون سرنشین quadrotor در صورت متوقف شدن چرخش یکی از چهار پایه ، فاجعه بار شکست بخورند. اکنون ، به لطف محققان دانشگاه صنعتی دلفت هلند ، هواپیماهای بدون سرنشین می توانند به پرواز خود ادامه دهند حتی در صورت از دست دادن موتور.

هواپیماهای بدون سرنشین معمولاً quadrotors هستند که از چهار موتور و روتور برای پرواز استفاده می کنند و این یک عدد دلخواه نیست. استفاده از چهار موتور - دو چرخش در جهت عقربه های ساعت و دو چرخش در خلاف جهت عقربه های ساعت - به طور ذاتی پرواز پایدار را فراهم می کند. این پهپاد را تا زمان آماده شدن جهت تغییر جهت ثابت نگه می دارد ، مانند روتور دم روی هلیکوپتر که با گشتاور موتور اصلی خنثی می شود. اما ، همان گشتاور باعث می شود در صورت خرابی یکی از چهار موتور ، کنترل کوادکوپتر از دست برود.
با این حال ، این تکنیک جدید ، در صورت وقوع آن پهپاد را تحت کنترل نگه می دارد. در صورت خرابی یکی از موتورها ، کوادکوپتر به سرعت می چرخد زیرا گشتاور متعادل موتورها مختل می شود. اما ، حتی با شروع چرخش پهپاد ، محققان توانستند آن را در پرواز نگه دارند. آنها این قابلیت را در یک تونل باد نشان می دهند ، جایی که هواپیمای بدون سرنشین می تواند موقعیت خود را حتی با باد شدید حفظ کند. با استفاده از همین تکنیک می توان به پهپاد این امکان را داد که حتی پس از تا حدی غیرفعال شدن به مقصد برسد.
